Crypto Intellect
Data Intellect
CryptoIntellect
Analysing data tends to be tricky without data to analyse. Market data in particular can be difficult or expensive to acquire in large datasets. So let’s do our part to make it easy: we’ve built a system to make it straightforward to capture crypto market data from a number of exchanges, and store it in a SQL database and/or local CSV files.
Purpose
The Data
CryptoIntellect is designed to provide you with a simple way to pull normalised candlesticks data from multiple exchange APIs. To ensure you are able to access, understand and track all of your data, CryptoIntellect returns all candlestick data entries in a simple and readable format which includes the following fields:
|
Timestamp |
Exchange |
Coin |
OpenPrice |
HighPrice |
LowPrice |
ClosePrice |
Volume |
Bucket_Interval |
|---|---|---|---|---|---|---|---|---|
|
(datetime) |
(string) |
(string) |
(float) |
(float) |
(float) |
(float) |
(float) |
(string) |
- Timestamp: This is the latest time to be included in the data interval
- Exchange: This is the name of the exchange from which this data entry has been pulled
- Coin: Ticker for the coin whose data is represented in data entry
- OpenPrice: The opening price of the coin for the data interval
- HighPrice: The highest price recorded for the coin in the data interval
- LowPrice: The lowest price recorded for the coin in the data interval
- ClosePrice: The last price recorded for the coin in the data interval
- Volume: Total volume of coin traded on the exchange over the corresponding data interval
- Bucket_Interval: The size of the data interval you are pulling candlestick data for
This app offers the chance to configure your own data output by offering two main options; a raw mode and a database mode. Our raw mode will mount a local directory to your app container allowing it to save candlesticks data to CSV files split by exchange and by date, on your local machine. Our database mode will allow you to pass a SQL database connection inside a local config file which will create a database called CryptoIntellectDB. Here we will create four tables:
- Klines_Data: containing all of the candlesticks data pulled down from the APIs
- Exchanges: containing the exchanges from which you are currently pulling data
- Coins: contains extra data on all of the coins currently being tracked by your CryptoIntellect
- MetaData: a bitemporal table for tracking and monitoring metadata of your Klines_Data table
It makes use of SQLAlchemy in order to safely handle your database mappings and connections, therefore you will only be able to integrate your CryptoIntellect app with an SQLAlchemy-supported database, see https://docs.sqlalchemy.org/en/20/dialects/index.html
CryptoIntellect will allow you to use one or both of these options for storing data, however, a config file must be provided during the startup of the app (see later) in order to access the database mode.
You can pull data from anywhere between the top 1 to 100 coins by market cap, as well as pull data on any specifically requested coins. Data is currently pulled from any of the four exchanges; Binance, Kucoin, Kraken and Poloniex. Although we do wish to add more exchanges for you in future updates, the current four exchanges should provide you with coverage of at least the top 100 coins by market cap. Your app will do all of its own data aggregation, therefore you will be able to bucket your candlesticks data to any interval you please regardless if it’s traditionally offered by the API.
You can configure your own data-pulling needs in the initial setup using a config file or by following simple instructions when completing startup (see below), providing you with an easy-to-use, customisable pipeline for whatever crypto project you are working on.
Using Database Mode
When using the database mode you get access to more than just a table storing your candlesticks data; we provide you with a coins table to track more general data on the coins you are currently tracking, an exchange table to control what exchanges are currently being pulled from and a MetaData table to monitor any changes in your candlesticks data. You can see the schema CryptoIntellect will use below:
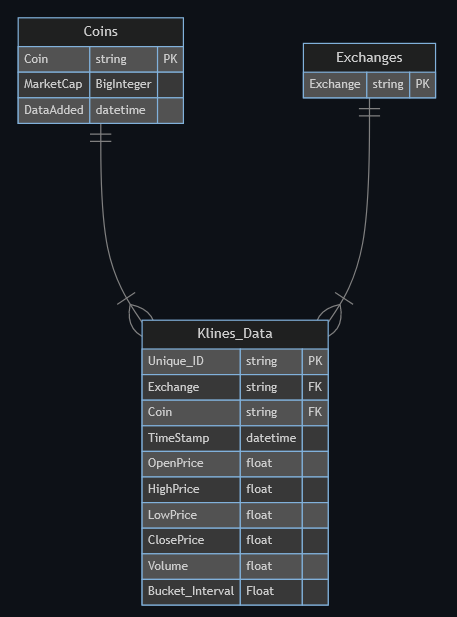
You can see your Klines_Data table has an additional column “Unique_ID”, this is added to ensure that no duplicate entries can be stored in your database and allow SQLAlchemy to map pulled data into your SQL database.
Feed Forward
Some exchanges when queried will not return any data for coins that have 0 volume for the requested data interval, leading to missing data entries which can affect your pattern recognition or quantitative analysis models. In order to solve this problem, CryptoIntellect’s database mode introduces a feed-forward method which will compare which coins are present in newly pulled data with all the coins in the database which have previously been returned from an API. If the latest data pull is missing any coins which have previously been returned, CryptoIntellect will retrieve the ClosePrice of the latest entries in the database of the missing coins and append new entries to the new data with all prices set to the latest ClosePrice and the volume set to zero for each of the missing coins.
Tracking your MetaData
It is often extremely important to monitor changes in the data you are storing. There are many important questions such as; What changes have occurred? When did these changes occur? When did you think these changes occurred? What did you believe the data looked like at certain points in time? Answering these can often be crucial when looking to analyse your performance or your model’s performance. In order to help you answer these questions, CryptoIntellect’s Database mode comes equipped with a bitemporal metadata table (check out this blog post for more information on bitemporal data; enjoy the principles with a seasoning of kdb+) which scans for updates in the metadata of the Klines_Data table every time you pull new data. The bitemporal nature of the metadata table enables you to keep track of what you believed the data to look like at any point in time, this is tracked by the Assertive_From and Assertive_To timestamps, and what the data actually looked like at any point in time, this is tracked by our Effective_From and Effective_To timestamps.

All of the logic to handle the bitemporal updates is done in Python and pushed to the database so you do not need to worry about whether your connected database is suited to handle bitemporal data storage in order to access the full features of CryptoIntellect’s database options. Check out this section of our readme to see an example of how our table works.
Backfilling Data
If you are using CryptoIntellect in database mode you will have the opportunity to backfill your database with candlesticks data from as far back as each individual API will allow you to track. After your application is successfully installed and running you can backfill your database by running one of the two following commands:
ci_backfill -f/--from "YYYY-MM-DD (HH:MM:SS)" -t/--to "YYYY-MM-DD HH:MM:SS"
docker exec -it cryptointellect_container python3 src/data_ETL_Jobs/backfill_historical_data_script.py -f/--from "YYYY-MM-DD (HH:MM:SS)" -t/--to "YYYY-MM-DD HH:MM:SS"Command 1 can be run if the application is set up using the installation bash script, otherwise if pulling the image yourself use command 2.
This will backfill your database from [date in command] to [date in command] while simultaneously allowing you to still capture real-time data. When running this simple command if you don’t include the –to tag you can simply backfill data until the current datetime. The HH:MM:SS part of the timestamp is optional – if omitted, it defaults to the very start of the day specified (00:00:00).
Running The Application
Your CryptoIntellect app is a dockerised data pipeline to pull your crypto data, however, in order to avoid a complicated docker setup, a bash script cryptointellect.sh can be found here within our public repo Crypto Intellect Install Script that’s available to download, to help you get your app running. This script takes care of the heavy lifting for you – it pulls down the docker image, assigns aliases to the necessary commands, builds, and runs the application!
Starting your CryptoIntellect app in raw mode couldn’t be simpler, all you have to do is locate the directory where the bash script is installed in your terminal, and execute the command:
source cryptointellect.shThis should start up your docker application in raw mode, with CSV files being saved to a local directory <your_working_directory>/cryptointellect/csv.
If you want to access CryptoIntellect’s database mode you will need to supply a config file at startup. Your local config file should be a .yml and should contain the same fields as the example below (see our readme for more information)
bucketing_interval: 3m
exchanges:
- Binance
- Kucoin
- Poloniex
- Kraken
database_connection: mysql+pymysql://root:root@database:3306
list_coins_to_poll:
- Safemoon
- Neo
- Optimism
n_coins_to_poll: 20
save_to_csv: true
save_to_database: false- bucketing_interval: A string, specifying the time bucket between pulling down data and aggregation. Specified in the format of a number, followed by either m (minutes), h (hours) or d (days). In the example above, ‘2m’ would equate to 2-minute buckets.
- exchanges: This is a list of exchanges that the application uses to pull down data from. By default, the application comes with 4 ready to use exchanges, shown above. Any number of the 4 above can be specified, if you would like to add your own exchange please reference the readme.
- database_connection: This references the connection string to a database provider. Can be MySQL, PostgreSQL, or any other supported database for SQLAlchemy, see https://docs.sqlalchemy.org/en/20/dialects/
- list_coins_to_poll: If you would like to poll specific coins, provide their names here. This list can be as long or as short as you like and will ensure the application is pulling down data for those coins.
- n_coins_to_poll: This specifies how many of the top n coins, in terms of market cap, are to be tracked. For example, 20 means that the top 20 cryptos in terms of market cap are being polled.
- save_to_csv: Boolean value used to save the output of the API calls to local CSV files, or not.
- save_to_database: Boolean value used to save the output of the API calls to a database, provided by the initial_db_connection string and the root_database_connection string.
Once you have built your local config file, running the app is simple: all you have to do now is attach your config file using the -c or –config tag
source cryptointellect.sh -c/--config <PATH_TO_CONFIG>Our bash script sets up aliases corresponding to different docker commands to help you manage your app, to view these commands just use:
source cryptointellect.sh -a/--alias If at any point during your app setup you run into problems you can just attach a –help/-h tag:
source cryptointellect.sh -h/--help
Windows
The windows batch script can be found here.
First, download this script and place it in your documents folder or desktop. This script will create the necessary folders needed, and these folders will be created in the same directory the script lives in.
Next, open either a windows command terminal or a powershell terminal and run the following command:
CMD: cryptointellect.batPowershell: .\cryptointellect.batAnd that’s it! Once the container is up and running, you can see the output of the application by navigating to the newly created cryptointellect folder, where the csv files will be.
To run with a custom config file, simply run the same command as above, but this time provide the file path to the config file after calling the script.
CMD: cryptointellect.bat <PATH_TO_CONFIG>Powershell: .\cryptointellect.bat <PATH_TO_CONFIG>This creates and starts a container named cryptointellect_container, which can be stopped and started with the docker commands:
docker stop cryptointellect_containerdocker start cryptointellect_containerRunning Manually
To run yourself without needing to download any of the scripts is easy! First, create a folder where you’d like your csv data to be saved. Next, run the two following commands:
docker pull public.ecr.aws/c5m8g6i6/cryptointellect:latest
docker run --name cryptointellect_container -d -v <path_to_local_csv_folder>:/src/csv_folder/:rw public.ecr.aws/c5m8g6i6/cryptointellect:latestThis creates and starts a container named cryptointellect_container, which can be stopped and started with the docker commands:
docker stop cryptointellect_containerdocker start cryptointellect_containerCustom Config
To run yourself with a custom config file, a little more is involved. First, create a file called config.yml, using our template within the readme for reference. Next, create a folder where you’d like your csv data saved, and create a Dockerfile containing the following:
FROM public.ecr.aws/c5m8g6i6/cryptointellect:latest
COPY <path_to_local_config.yml> /src/
RUN python3 src/Initial_startup.py
CMD ["cron", "-f"]Next, open a terminal within this folder and run the two following commands:
docker build -f Dockerfile . -t cryptointellect
docker run --name cryptointellect_container -d -v <path_to_local_csv_folder>:/src/csv_folder/:rw cryptointellectStill Got Worries?
There are a number of issues you are probably wondering about, such as: Does waiting on all these I/O bound operations mean that the pipeline could potentially become very slow? How can we scrape all this data for free, from public APIs? While these can be issues when trying to pull your own crypto candlesticks data, they are not something your CryptoIntellect app will run into.
While you are running the CryptoIntellect app you are pulling data from free crypto exchange APIs which can enforce strict rate limits, leading to your IP address becoming blocked when reached, this will not create any issues for your pipeline. Your CryptoIntellect app has its own built-in limiter class which we use to decorate our request methods. The class decorator will take in the number of requests and a time period as arguments to ensure that the request method never sends more than the specified requests in the allotted time therefore never hitting the rate limit for the API.
class Limiter:
"""Decorator class that will restrict the number of asynchronous tasks an asyncio method can make per second"""
def __init__(self, calls_limit: int = 5, period: int = 1):
self.calls_limit = calls_limit
self.period = period
self.semaphore = asyncio.Semaphore(calls_limit)
self.requests_finish_time = []
async def sleep(self):
if len(self.requests_finish_time) >= self.calls_limit:
sleep_before = self.requests_finish_time.pop(0)
if sleep_before >= time.monotonic():
await asyncio.sleep(sleep_before - time.monotonic())
def __call__(self, func):
async def wrapper(*args, **kwargs):
async with self.semaphore:
await self.sleep()
res = await func(*args, **kwargs)
self.requests_finish_time.append(time.monotonic() + self.period)
return res
return wrapperIn order to ensure your pipeline works as efficiently as possible and to address the problem of awaiting the API response, which can be painfully slow at times, CryptoIntellect uses a few different methods. Firstly, we split data pulling from different exchanges into different threads, with the help of Pythons standard library multiprocessing package. This means you are able to pull data from multiple exchanges at the same time, saving you the time of having to wait for one exchange to finish processing before moving on to the next. In order to solve the slow I/O bound tasks we introduced asynchronous requests using Pythons asyncio package. Asynchronous routines are able to pause while awaiting a result to allow further execution of code, allowing concurrent tasks to run on a single thread, so your pipeline is never idle. This in combination with other optimisation steps means that your pipeline is only limited by the API request limit rates.
Expanding
CryptoIntellect is a dockerized pipeline that pulls candlesticks data, performs data quality checks, normalises the data and saves to a user-defined output. The steps required to pull data from each exchange are the same; request data, normalise it and perform quality checks, however, the logic needed to achieve each step varies based on the API’s response format. To reflect this behaviour, each exchange we pull data from is represented by a separate class, with each of these classes inheriting an abstract base exchange class containing all abstract methods which will need to be created before an exchange class can be instantiated. Using inheritance for each exchange class allows for the individual logic requirements for each exchange API to be met while allowing for generic Python scripts to be run as part of the pipeline, with the only requirement that the classes passed as arguments are of type BaseExchange. Check out Base.py and Binance.py for more information.
Once in the docker container, you are more than free to manually change the config file values. All you have to do here is edit src/config. After changing any values, don’t forget to run the Reset_Config.py script to apply these changes.
Our Code
If you are interested in checking out the code of your CryptoIntellect pipeline, have a look at our GitHub page at Crypto Intellect
Share this:
















