Deephaven as a Tool for Real-Time analytics: The Basics
Data Intellect

What is it?
Deephaven is an open-core framework, query engine, and versatile UI/UX framework designed for real-time analytics and live apps, combining dynamic data, such as streaming tables, with static data to allow a unified approach to cleanse, process, and share data at scale. At heart, Deephaven allows the handling of relational data, streams, and time series with the simplicity and flexibility of Pandas at a much greater scale and with an eye on performance. As we’ll see below, under the hood columnar chunks of data are addressed by an incremental update model, offering big efficiencies by working on table-changes rather than using a traditional microbatch approach. The update model combined with a slick wire protocol (an Apache Arrow Flight extension!) allows efficient consumption, collaborative, multi-node graphs, table operations and user defined functions, all in real time.
How to treat real-time data use cases in a general purpose table-oriented data system


How to provide real-time tables between multiple nodes of a system
And to do it efficiently, without the cost penalties associated with serialization.
Real-time Tables
In general, real-time (or even frequently updated) systems need to overcome a significant obstacle: combining streams and tables. Unification isn’t so straightforward; both types of data come with distinct advantages and trade-offs. For example, streaming data is typically quite small as it only considers the new data, keeping the problem space and required resources constrained. Data-driven applications often require many steps and logic chains to natively handle streaming data in a traditional static relational setting.
On the other hand, these traditional relational data sources are the opposite – while typically good at dealing with large tabular data, adding new data often requires re-evaluation of the entire dataset, resulting in a negative impact on a variety of fronts such as time to market, performance and cost of computation.
Deephaven solves this neatly by employing a DAG (Directed Acyclic Graph) approach, which models the relationships between tables and their dependents to unify the data methodologies of streaming data and table structures. In simple terms, each table or mapping between tables is a “node”, and these nodes are interconnected by listeners which communicate and apply updates between parent and child tables. These listeners can also connect outside the Deephaven ecosystem and connect to external sources such as SQL databases or financial data vendors. Changes flow through the DAG via these listeners each cycle to efficiently micro-batch updates in a highly scalable fashion.
Deephaven tables are treated as ordered streams called Row Sets. These are ordered sets of rows mapped against a column source. To reduce redundant data, tables can share Row Sets and column sources. For example, child tables form enclosed Row Sets that use their parent.
Chunking and graph dependency combine to give the flexibility of streaming updates with the utility of table-like interfaces. A combination of streaming inputs can be queried, transformed, and generate new dependent tables effectively and efficiently.
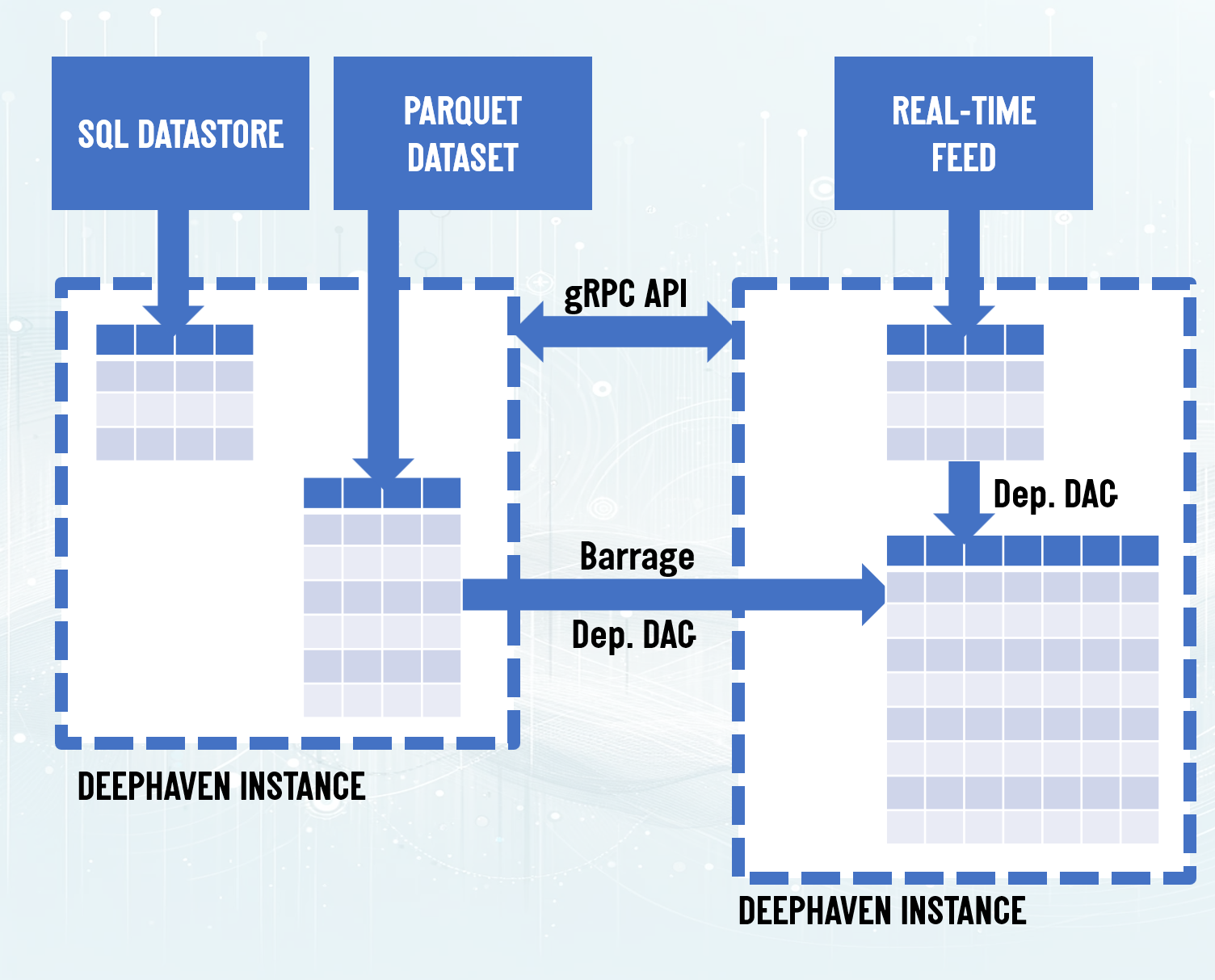
Efficiency in a multi-node system
To aid in the transport challenge inherent in the multi-node configurations that modern, sophisticated use-cases demand, Deephaven embraced gRPC and Apache Arrow Flight, building an extension called Barrage. In simple terms:
gRPC is a popular framework developed by Google, serving countless environments across industries. The gRPC (Remote Procedure Call) framework allows efficient, scalable connections between services in a flexible, language-agnostic format.
Arrow Flight is a highly efficient client-server transport framework which provides Deephaven a method of communication by leveraging Arrow’s model of core tables and Flight’s work on wire streaming transports.
These tools are combined under Deephaven’s API to create Barrage – an API which allows for custom metadata around Row Sets to incrementally change data with the Deephaven update model. Additionally, Arrow allows for zero-copy writes and zero-copy reads, removing unnecessary translation costs when moving data from one server to another for further efficiency gains.
In a nutshell, gRPC and Arrow Flight combine with a bespoke Deephaven update model to maximize the throughput between data sources under the moniker of Barrage. Barrage is essentially the cornerstone technology that brings the power of Deephaven’s incremental update model outlined above to modern multi-process architectures; this provides the flexibility to integrate a wide variety of sources with the internal consistency for domain-specific data-driven applications and real-time analysis at scale. The diagram to the left shows an example of multiple Deephaven instances communicating via the gRPC API, and extending the subscription DAG “over the wire” to another instance, using the Barrage protocol, so that Row Sets can be combined and updated. Note, finally, that gRPC isn’t just for Deephaven-to-Deephaven communication, but can reach out to other data sources, too. Check out the link below for more information.
Query Language Considerations & Some Basic Examples
Before we begin, it’s important to note that Deephaven leverages a unified API: no matter what data source a developer is working on, the syntax remains the same. A developer running calculations on real-time data works the same way as a developer working solely on historical sources. Additionally, an engineer can choose to use Python, Java, or Groovy to write queries server-side or to interact via idiomatic clients in Python, Java, C++, Go, and R. All queries in Deephaven are Java “under the hood” – the Python API simply wraps the underlying Java engine, leaning on a bidirectional bridge called JPy that the Deephaven team seemingly helps maintain.
In practical terms though, there are two penalties to using Python. First is crossing the Python-Java JPy bridge. As we’re calling methods in Java from Python, we incur a translation/wrapper cost. Second is encountering the GIL (Global Interpreter Lock). This plagues Python at scale by preventing concurrency in favour of single-core performance. It is therefore up to the developer to avoid crossing this bridge as much as possible.
Another consideration for real-time data is the handling of timestamps and mathematical operations. In Deephaven it is highly encouraged to use the built-in methods or Java methods where possible. Below is a simple example:
The burden of sin
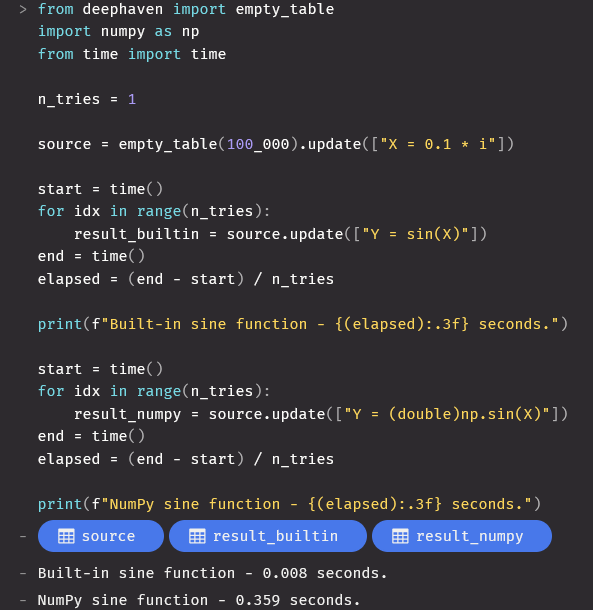
We start with NYSE quote data – a small sample of 100k rows. In this example, we simply calculate the time taken for the built-in sin function compared to the numpy sin function in an identical setting. When we calculate the sin function for a single system, the built-in Java sin function takes 9 ms compared to the 359 ms required for numpy. That’s almost 40 times faster! Why such a drastic difference for such a simple calculation? To answer simply, the JPy boundary is crossed twice in this example – once when going from Java to Python to calculate X and a second time back the way from Python to Java. Luckily we don’t have to cross it for every single data element, but each chunk will need to cross the boundary twice, further ramping up the costs of picking the inefficient approach.
In contrast, the built-in method does not cross the JPy boundary at all saving precious time and computational resources.
Though Deephaven is built to serve Python developers directly, in some cases it may make sense to rely on Java.math or Java.time methods within one’s Python scripts to avoid unnecessary translation. As seen in this example, the Java Groovy syntax cuts down on dependencies and by extension complexity. Remember, all functions in the Deephaven Python API are simply Java functions with a small amount of initialization overhead for convenience and speed. Thus, as you can see the best way to use Deephaven is by leveraging the feature-rich Java standard libraries interwoven into the Deephaven DNA, improving efficiency throughout our Deephaven queries.
Filters and groups
As a unified API, Deephaven contains a range of useful built-in functions. In particular two spring to mind:
First and foremost is the highly optimized set of filters – in particular the “where” command acts as the focal point of filtering. It is, however, worth noting that matching filters such as “in”, “==” or “not in” are much more efficient than conditional ones such as “>” (greater than) or “<=” (less than or equal to) and as such should be chained with matching filters first. Best practices for highly controllable filter languages apply – use cheap operations to remove as much data as you can as quick as you can.
Filters
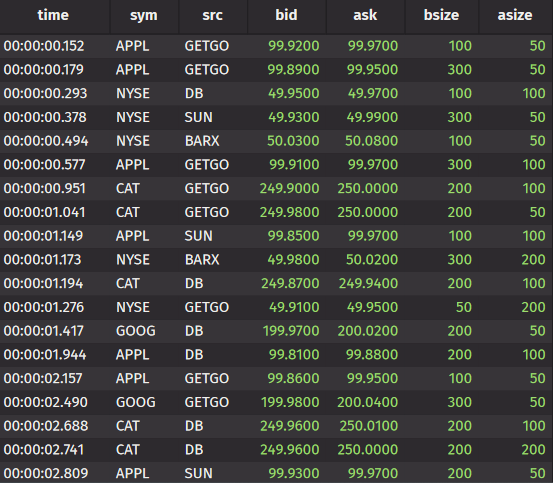
Consider this sample data table called “quote”, with 400,000 rows of simple data. In this table, we can see a handful of string columns such as “sym” and “src”, as well as the float columns “bid” and “ask”. We can, of course, filter the string columns by exact values and the numerical ones by conditional ones.
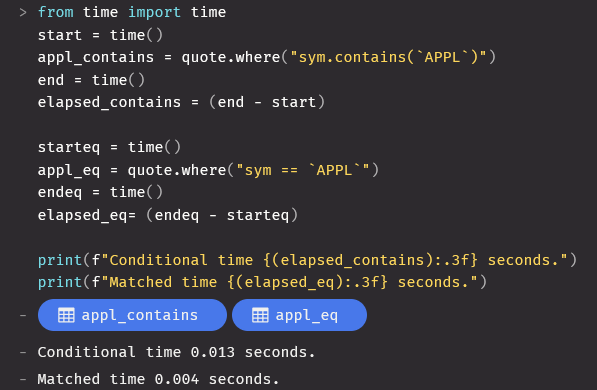
Exact vs Conditional
As seen in these example filters, the first 2 filters “appl_contains” and “appl_eq” produce the exact same results as they are roughly equivalent filters. The first, “appl_contains”, however is slower as it is a conditional filter, where as “appl_eq” is a matching filter. From the data, we can see that the matching filter is roughly 3 times faster at 4 ms compared to 13ms. That’s pretty significant!
Filter fast
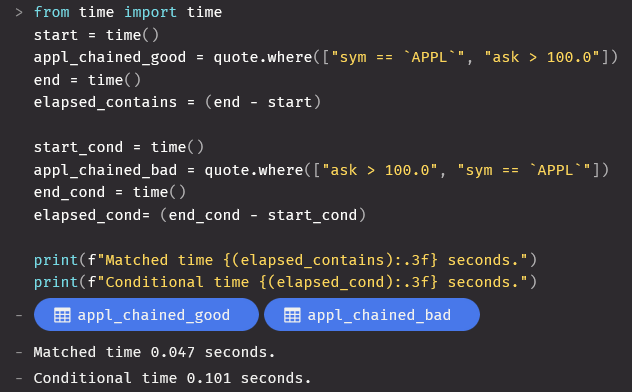
Finally, in the example filter, “appl_chained”, we start with our matched filter which is equivalent to “appl_eq” chained to a conditional filter to return only rows where the “ask” value is greater than 100. As you can see, the matching filter, aptly named “appl_chained_good” is roughly twice as fast as the less efficient “appl_chained_bad” which begins with the conditional filter. As common sense would dictate, this is due to the “ask” conditional filter first scanning all rows and by extension all values of “sym” before filtering down to only “appl” meaning significantly more work for the same results.
In summary, by thinking like a Deephaven ninja and correctly optimizing our already very flexible filters, we can tune already lightning-fast performance to squeeze out even more with a few simple considerations! Isn’t that cool?
The second key operation is update_by – this keyword allows us to apply a range of one or more “UpdateByOperations” to a source table. These include windowed aggregations, cumulative sums, moving or rolling averages and many more. The interesting part is that update_by works on both historical data as well as real-time streaming data with no changes at all!
Considering the above “quote” table, we can apply some of the same filters as before and then perform an exponential moving average of the values of the bid. This is achieved using the below code snippet:
from deephaven.updateby import ema_tick
appl_ema = appl.update_by(ops=ema_tick(decay_ticks=2, cols=["EmaBid = bid"]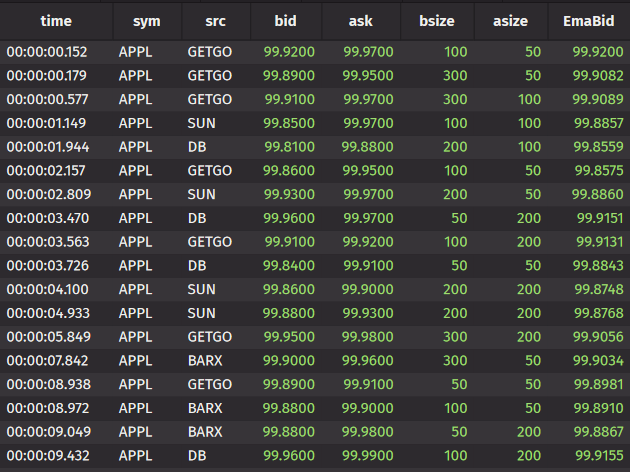
Live results
This is our resultant table. The new column EmaBid has been applied to the source table and if new data is added, this will tick over time, updating with each new row added. Remember the incremental update model mentioned earlier? This is the perfect example of that in full flight! However, it’s worth noting that currently only built-in update_by operations are possible – but the library of functions is constantly growing.
As you can see
Deephaven is built to combine the versatility of Python with the speed of Java to create a tool capable of replacing a myriad of real-time and historical data solutions in one neat package. The “killer app” features, the unified API in particular, make Deephaven a competitive player in the real-time market. The convenience and ease of use offered by the Python client also means that less technically proficient users can leverage both the simpler syntax and the web UI to analyse data independently. The ever-growing feature set offered by Deephaven community, and the extensible nature offered by the millions of Python packages available to install, also cement Deephaven as an ever-improving Swiss army knife in the real-time space.
With many more features, such as real-time ingestion and a range of interesting I/O methods offered by Deephaven we don’t have the space to go into in this post, the wealth of features offered in Deephaven is yet untapped and we’re excited to cover more in the future.
Share this:
















