A Tight Scrape
Ryan McCarron
So, I was wondering...
Recently a colleague came to me with an interesting question – can we crawl the entire internet looking for where people are talking about a certain topic? Can we get updates when those locations or the contents change? Of course: challenge accepted.
Crawling the entire internet takes quite some time, as even a small fraction is in the tens of hours for mere mortals. As fun as that would be, let’s get more efficient.
When thinking of another solution, the key question is “what’s the time horizon?” If it’s instant updates as soon as the sphere of human knowledge changes, we’re going to need quite the budget. If it’s once every six months, maybe it should be a manual task. Instead, it’s once every day or two – if some website mentions the topic, we should be able to update our own internal knowledge within a few days.
That puts us right in the perfect place to use something already crawling the web, and updating most pages in its index within hours or days: Google. The search results page gives us the “best” places people are discussing the topic at hand.
So how are we going to get Google search results in a format that someone can take away and use? Legend speaks of a Google search API , but it was shut down in 2008, 2010, 2014, and 2016. Some say it’s still being shut down today. Either way, it’s unusable. There are paid services which provide an API for us, but this is an interesting problem. I think we can turn to our old friend web scraping for answers; that is, programmatically retrieving data from web pages.
Web scraping is usually straightforward, and tutorials abound. The approach is, from a command line or script:
- Pull down a webpage, HTML, CSS, JS etc.
- Use something to parse it into a searchable format.
- Lift out the bits you want, usually tagged or classed as something convenient.
My preferred approach for this is just to use the python requests package to get the page, and parse it with the extremely useful package BeautifulSoup.
Let’s try it with an example search:

The browser tells us all about what other people think of ourselves. What does a http GET request return?
import requests
requests.get('https://www.google.com/search?q=%22data+intellect%22').text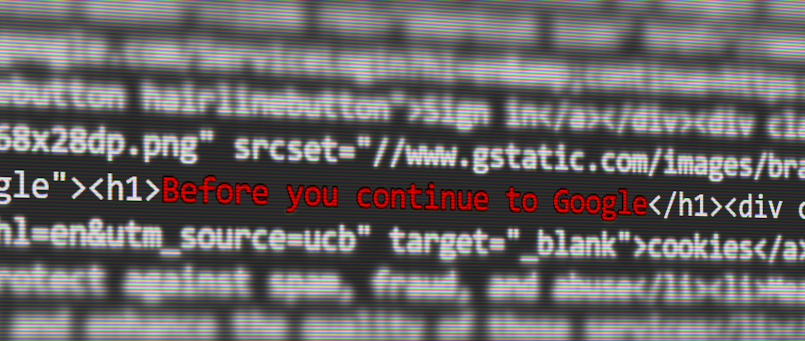
We’ve all seen this before when first visiting Google, but it’s usually in its own pop-up, and the results are still there. Instead, Google is rendering only this page while grinning smugly. It knows we’re not real.
So let’s try another approach. What we’re doing when we send requests.get is pretending, badly, to be a web browser. We have default headers which we should change, and a number of other tell-tales. We could fix these. Or, we could just use a web browser.
Chrome, Firefox, and other modern browsers offer a “headless” mode where they run without a GUI. To manage an instance of, say, Chrome, running headless from the command line we need to use Selenium, a python package designed originally for testing web browsers.
Selenium, on its own, isn’t enough. We also need to install Chrome, and manage a webdriver used to handle the Chrome connection. We’ll manage all of this in an Ubuntu docker image (Ubuntu 20.04.6, specifically), for neatness and dependency management. The complete code is in this gist.
The Dockerfile is extremely simple:
FROM ubuntu:focal
COPY googleScraperSetup.sh /googleScraperSetup.sh
RUN /googleScraperSetup.sh
COPY googleScraper.py /googleScraper.py
CMD python3 /googleScraper.py >/pyoutlog.log 2>&1And our environment setup is straightforward too:
#! /bin/bash
apt-get update
# Install with a non-interactive frontend to get around asking for a timezone
# Otherwise, this is a dependency for Chrome
DEBIAN_FRONTEND="noninteractive" apt-get -y install tzdata
apt-get install -y pip wget
# Strange version clash – libudev needs to be downgraded
apt-get install -y libudev1=249.11-0ubuntu3
# Download and install Chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
apt install -y -f ./google-chrome-stable_current_amd64.deb
# Basics
pip install selenium BeautifulSoup4 pandasInstalling Chrome on a blank Ubuntu container is a dependency labyrinth. Thankfully, “apt install -f” does all the hard work for us, pulling dependencies where needed. The only issue I ran into is libudev requiring a downgrade to the above version, which apt couldn’t handle for me.
Scraping a page with a headless browser is surprisingly painless.
# Lots of imports
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument('--headless=new')
# These two arguments stop the headless instance from falling over when it tries to render video
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
# This helps target pages render as if they were on a monitor
options.add_argument("--window-size=1920,1200")
# This tries to use the latest driver available for the Chrome version used, installing if needed
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get("data intellect" -site:dataintellect.com)
page = driver.page_sourceThe webdriver manager above downloads the required latest compatible driver for us (phew), and the option ‘—headless=new’ is (as the name implies) a new method for adding a headless view introduced in the last year. The rest of the settings prevent the Chrome instance attempting to display something and losing its marbles.
The result then is “page”, roughly equivalent to the result from requests.get above, but instead, showing the actual results from a google search. Hooray! But we aren’t done yet.
Let's strain the soup
We need to make sure we can actually glean useful information from the page result. First step is to convert this into a navigable, searchable tree with BeautifulSoup, as in the code snippet below. This soup groups all the elements into a tree, similar to what you can observe in the page inspection below. You can find elements of a certain class, ID, type, etc, and once found move to adjacent elements or to parent or child elements, inspect and retrieve attributes, or pull out data.
After making our soup, we’d look for the elements we want to pull out and condense them into a results table. Frequently when webscraping, these are tables, lists, paragraphs etc which have been tagged with a sensible ID or class. You can, for example, find all tables, pull out the elements, and congratulate yourself (and the BeautifulSoup team) on a job well done. So, what does Google give us to make this easy?
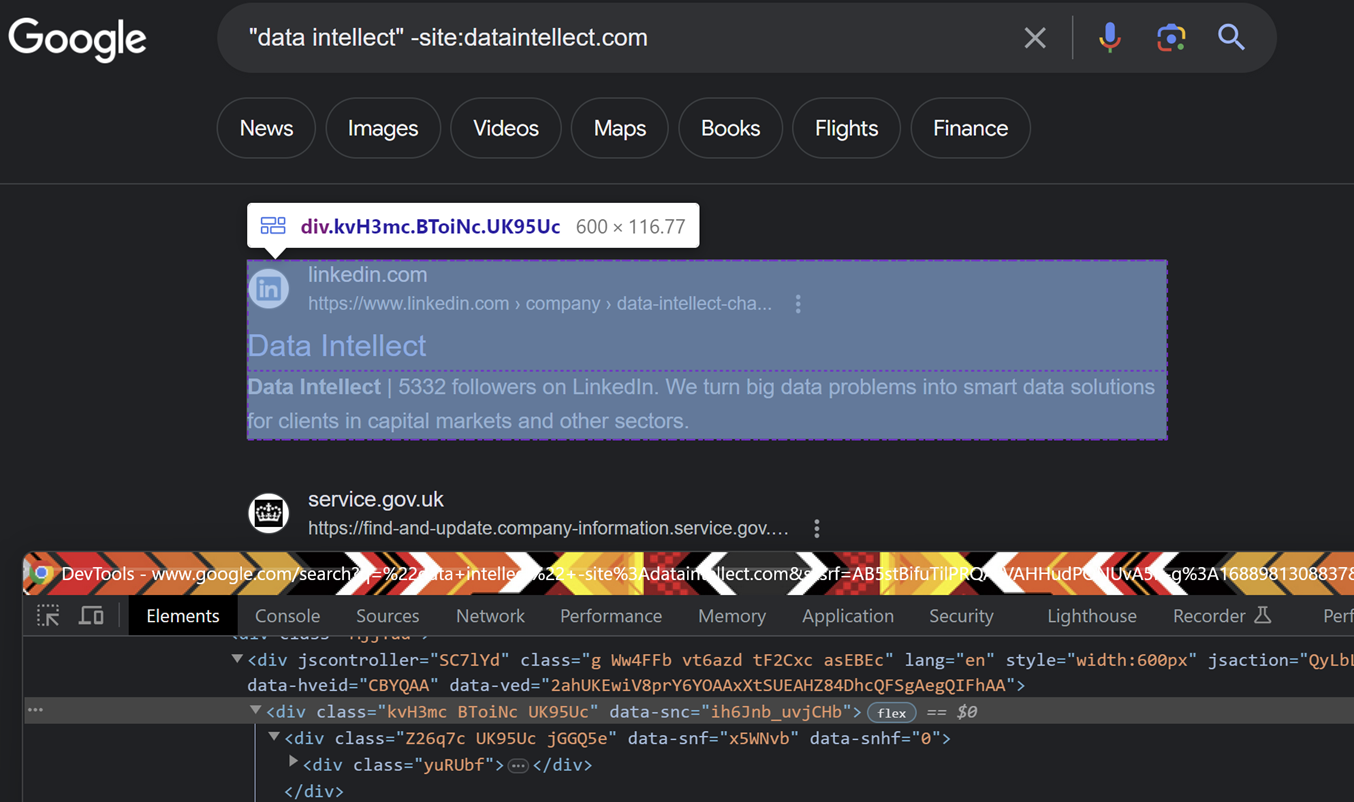
Nothing. Of course. The classes are obfuscated.
We’ll need to get creative. We know each results page should have around ten results. Those results are broadly grouped to have a headline link (“Data Intellect”, pointing to LinkedIn above) and a blurb. There might be more, too, such as an image or secondary links, but this is enough to get started.
The inspection shows us all items here are divs. We have the rough shape of what we’re looking for:
- A div whose class is present 6-12 times, one for each result
- These divs each have at least two children (that is, div elements contained directly in them)
- One of these children has a URL
- One of these children is a blurb
We can use the inspection tool in Chrome to poke around at a rendered page, and after a little manual inspection, we can see that, among the mess of tags, the blurb divs all contain ‘data-snf’ as an attribute. As well, the first URL in the primary div for each result is the link we want to retain, so we can probably drop that from our set of child checks.
So we simply write something to look for any div with the right characteristics. We’ll pull out all the divs in the entire page, and count their frequency.
soup = BeautifulSoup(page, 'html.parser')
divd = {}
divs = soup.find_all('div')
for x in divs:
if x.has_attr('class'):
# Reconstruct div class to inspection state
cn = ' '.join(x['class'])
# Count them up
divd[cn] = divd.get(cn, 0) + 1Then we can define some helpers to pull out the div we actually care about:
def checkDivClass(soup, d):
chk = True
for x in soup.find_all("div", {'class':d}):
# Should have at least 2 children
c = list(x.children)
chk &= 2<=len(c)
if not chk:
return
# Second child should have 'data-snf' attr
chk &= c[1].has_attr('data-snf')
if chk:
return d
return
def getDivClass(divd, soup):
for a,b in divd.items():
# Check there are between 6 and 12 appearances
if 6 <= b <= 12:
# Verify against other criteria
if v := checkDivClass(soup, a):
return v
returnand, upon getting the right class of this div, we can find them all, and pull out the title, URL, and blurb:
res = [] #placeholder
for a in soup.find_all('div',{'class':divClass}):
b, c = list(a.children)[:2]
title = next(b.strings)
url = a.find('a', href=True)['href']
desc = c.text
res.append((title,url,desc))We can throw this into a pandas DataFrame and, at last, a sensible set of results. The first page ended up containing 9 results:

We can take these results and wrap them in a nice plaintext/html multipart message, ready for daily email updates to anyone interested. You can see that here.
Web scraping is notoriously fiddly, and these search pages were trickier than most – but with a little consideration of what’s given to us, this becomes a much simpler problem than it seems at the outset. As I press publish, this has been running without issue for a few weeks, but at some point Google will change their page structure in a way that side-steps some assumption we’ve made above. But that’s fine. We’ll accept that challenge, too.
Share this:
















