Ciaran O'Donnaile
Introduction
Turn on a TV, open a newspaper or scroll on your phone for a few minutes today and you will undoubtedly come across some reference to Machine Learning or Artificial Intelligence. These terms have become ubiquitous, but they are more than just buzzwords. From healthcare to finance, entertainment to energy, artificially intelligent applications are revolutionising industries. At the core of this trend lies a vital but often under-discussed component: the databases that store and manage the vast quantities of data needed to power these AI systems.
At Data Intellect, we have been exploring the utility of AI applications and how they could be of benefit to us, both in the short and long term. We envisage an AI tool that works alongside human counterparts, offering support that enhances both learning and productivity. Such a system would allow engineers to pose context-specific questions and retrieve accurate information at speed. Reaching this goal involves a process of continued learning, experimentation, and fine-tuning. Through our blogs, we aim to share each step of this journey with you.
In this blog, we’ll be experimenting with KX’s latest offering, KDB.AI; a vector database optimised for Natural Language Processing and Generative AI search applications. We’ll look briefly at its current functionality, before developing a prototype TorQ support bot based on the Retrieval-Augmented Generation (RAG) framework using LangChain, with KDB.AI as our underlying vector database. We will name this system TESS (TorQ Expert Smart Support).
TorQ is a widely used kdb+ framework, and we regularly field questions about it. Questions arising externally tend to come from TorQ clients investigating new functionality who may be having issues or finding bugs, whereas internally they usually come from our new graduates as they get up to speed on kdb+ and the TorQ framework. The motivation behind TESS is simple: We have a wealth of documentation, blogs and code at our disposal, so why not leverage that to automate the handling of simpler questions? For TorQ users, whether internal or external, a context-specific QA tool like this would mean faster insights and more efficient workflows, streamlining the development process and negating the need for time-intensive searches through documentation, blogs, or StackOverflow threads. For our support crew, this also means more time to focus on higher priority tasks.
What is KDB.AI?
Many modern AI/ML applications represent raw data, whether it’s text, images or sound, as high-dimensional vectors known as embeddings. Traditional databases, with their rigid structures and focus on exact matching of scalar values, are often ill-equipped to handle the volume, velocity and high-dimensionality required by such applications. This is where vector databases come in, and where KDB.AI promises to make an impact.
In short, KDB.AI is a powerful example of a knowledge-based vector database that can be used as the basis for scalable, real-time AI applications. Unlike traditional databases, vector databases like KDB.AI are optimised for storing and retrieving embeddings, offering advanced in-built indexing and similarity searching methods, ensuring efficient storage, quick access, and rapid retrieval.
Retrieval-Augmented Generation (RAG)
Popularised by chatbots like OpenAI’s ChatGPT, Large Language Models (LLMs) have taken hold in recent years, largely due to their remarkable capabilities in interpreting and generating human-like text. They do, however, face a significant drawback in that many out-of-the-box models are essentially frozen in time, operating within the static knowledge snapshot captured at the time of their training. For many organisations, there is also the challenge of integrating their own data and commercial knowledge bases in their applications, whether it’s due to privacy or segmentation concerns. Whilst it is possible to retrain or fine-tune LLMs, the computational resources, data, and time required to do so mean that such options often offer a poor return on investment, ruling them out for many commercial applications. To bridge this gap and address the need for specialised, real-time information, the concept of Retrieval-Augmented Generation (RAG) has emerged as a powerful solution.
In their seminal 2020 paper, Facebook AI Research proposed a framework much like the one outlined in the figure below. The idea is quite simple. When presented with a query or a prompt, the RAG system doesn’t jump straight into generation. Instead, it makes use of a retriever model which searches through a corpus (database) of documents to find any “passages” or “chunks” of information that are relevant to the provided prompt or query. This is done by transforming both the query and the documents in the corpus into vector embeddings. The most relevant passages are then selected based on some predefined similarity metric between the prompt provided and information stored.
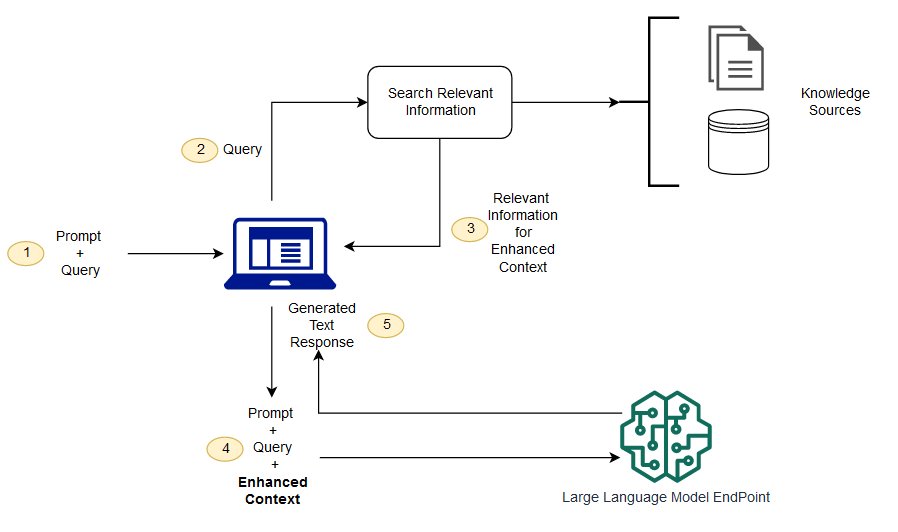
Once these passages are retrieved, they are not simply returned verbatim. Instead, they serve as context or a foundation for the generative model, often a large transformer network, which takes both the original query and the retrieved passages to generate a coherent, detailed, and contextually appropriate response. By combining both retrieval and generation, RAG has the potential to offer the best of both worlds: the specificity and accuracy of retrieval models with the fluency and coherence of generative models.
Key to any successful RAG system is the deployment of a robust vector database that can be used to store and query the embeddings. In what follows, I outline how I went about creating a basic TorQ support agent, let’s call it TESS (TorQ Expert Smart Support), using the RAG framework with KDB.AI as our underlying vector database.
The Code
Install Dependencies
The first step is to install and load the various dependencies, including kdbai_client to connect to KDB.AI and all the necessary LangChain and OpenAI libraries.
%pip install ipython jupyter pandas pyarrow openai pypdf tiktoken kdbai-client git+https://github.com/KxSystems/langchain.git@KDB.AI#subdirectory=libs/langchain -q from getpass import getpass
import os
import pandas as pd
import kdbai_client as kdbai
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import KDBAI
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chainSet API Key
To follow this example, you will need to request an OpenAI API Key. This can be created for free by registering through the link. Having set-up your account, your key can be provided as below.
os.environ['OPENAI_API_KEY'] = getpass('OpenAI API Key: ') Data Preparation
The next step is to prepare the data. Firstly, I used Beautiful Soup, a Python package for parsing HTML and XML documents, to scrape the TorQ documentation and blog posts before writing any text down to a single TorQ_RAG.txt file. The TXT file is then read, and the document split into chunks. It’s worth noting that there are several approaches to chunking text, ranging from straightforward divisions by paragraphs, sentences, or character counts, to more advanced methods employing natural language processing (NLP) models. The utilization of NLP models can enhance the effectiveness of text segmentation by understanding context and semantic boundaries. Such approaches will be considered in future iterations of the system, but for the purposes of this blog we will stick with LangChain’s ‘RecursiveCharacterTextSplitter’. Striking a balance is essential when determining chunk size and overlap. We want both to be sufficient to capture context and semantics, yet not so large such that we begin to sacrifice detail in our responses. After some experimentation, I have gone for a character count of approximately 200 with an overlap of 50 characters, which seems to work well for our purposes.
#Load the documents we want to prompt an LLM about
loader = TextLoader('./TorQ_RAG.txt')
doc = loader.load()
#Chunk the documents using langchain's text splitter "RucursiveCharacterTextSplitter"
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 200,
chunk_overlap = 50
)
#split_documents produces a list of all the chunks created, printing out first chunk for example
chunks = text_splitter.split_documents(doc)
texts = [p.page_content for p in chunks]The final step in preparing the data is to choose an embedding model. We will use OpenAI’s text-embedding-ada-002.
embeddings = OpenAIEmbeddings(model='text-embedding-ada-002') Enter KDB.AI
To connect to a KDB.AI cloud instance, we first need a hostname and an API key. To get these, you can sign up for free here. It is then possible to set a handle to your KDB.AI session:
print('Connect KDB.AI session...')
KDBAI_ENDPOINT = input('KDB.AI endpoint: ')
KDBAI_API_KEY = getpass('KDB.AI API key: ')
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)Before we can store any embeddings, we must first create a KDB.AI table. This involves defining a table schema. Notably, we must set the similarity searching metric and our preferred indexing method. I have chosen to opt for a Euclidean distance similarity search and flat indexing. Whilst flat indexing is slow and inefficient (there’s a reason it’s known as the ‘brute-force’ method!), it is also highly accurate. Due to the relatively small size of our dataset, this decrease in speed in favour of accuracy is acceptable.
## Setup table for vector store later
schema_rag = {'columns': [ {'name': 'id', 'pytype': 'str'},
{'name': 'text', 'pytype': 'bytes'},
{'name': 'embeddings',
'pytype': 'float32',
'vectorIndex': {'dims': 1536, 'metric': 'L2', 'type': 'flat'}}]}
print('Create table "rag_langchain_torq"...')
table = session.create_table('rag_langchain_torq', schema_rag)Finally, we can store our text data and embeddings in KDB.AI:
vecdb_kdbai = KDBAI.from_texts(session, 'rag_langchain_torq', texts=texts, embedding=embeddings)Now we have the vector embeddings stored in KDB.AI we are ready to create the bot!
ChatGPTorQ
There are four ways of approaching question answering (QA) in LangChain: load_qa_chain, RetrievalQA, VectorstoreIndexCreator, and ConversationalRetrievalChain. The method most in line with the RAG framework outlined above is RetrievalQA, which retrieves the most relevant chunks of text and proceeds with QA based on that subset.
The code below defines a question-answering bot that integrates OpenAI’s GPT-3.5 Turbo with a retriever that queries the KDB.AI vector database to extract relevant data.
K = 10
qabot = RetrievalQA.from_chain_type(chain_type='stuff',
llm=ChatOpenAI(model='gpt-3.5-turbo-16k', temperature=0.0),
retriever=vecdb_kdbai.as_retriever(search_kwargs=dict(k=K)),
return_source_documents=True)‘K’ is the number of relevant ‘chunks’ of information we would like to pass to the generative model. As we will see in the next section, our choice of 10 seemed to yield acceptable responses, however future work might reveal a more optimal choice. It may also be that alternative methods, such as reranking, where retrieved chunks are reordered based on their relevance before they are passed to the generative model, would be more suited.
Results
Our QA bot is now up and running! Below you’ll see a sample of the first few responses to give a taste of how it performs:
query = "How do I set up a standard tickerplant process?"
print(f'\n\n{query}\n')
print(qabot(dict(query=query))['result'])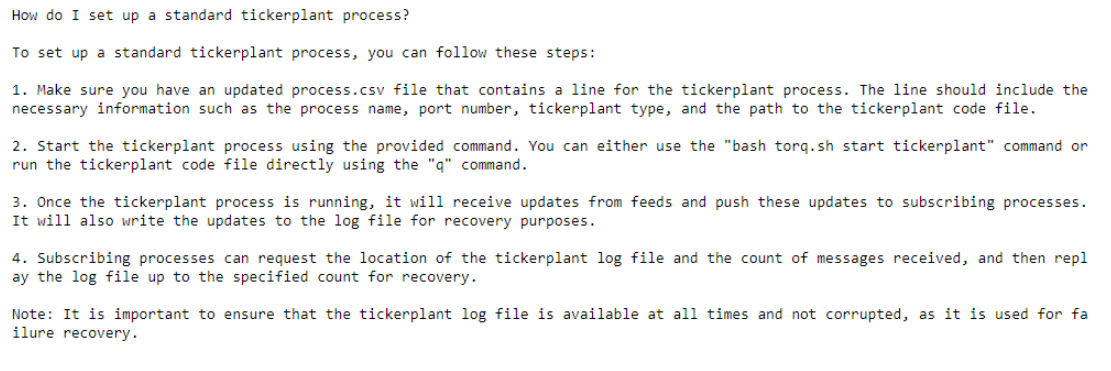
query = "How can I improve the performance of frequently run queries in TorQ?"
print(f'\n\n{query}\n')
print(qabot(dict(query=query))['result'])
query = "How can I make tickerplant subscriptions use unix domain sockets?"
print(f'\n\n{query}\n')
print(qabot(dict(query=query))['result'])
Promising, right? Whilst not always perfectly accurate, the responses tend not to be very far off the mark. With that said, some answers do come across as somewhat vague or lacking in detail. We’ve discussed several options that could be explored to help to improve our responses, but one avenue we haven’t discussed yet is base prompt engineering. Optimising a base prompt for our system could take some effort, but even a simple addition like “In TorQ” seemed to enhance clarity, leading to richer responses, as you’ll see in the upcoming example.
query = "How can I make tickerplant subscriptions use unix domain sockets?"
print(f'\n\n{query}\n')
print(qabot(dict(query=base_prompt + query))['result'])
Conclusion
Through this exploration of KDB.AI and the implementation of the RAG framework, we’ve seen the potential of combining retrieval and generation methods for accurate and context-specific question-answering, particularly in enterprise scenarios where extensive fine-tuning may not be feasible. Our prototype bot, though impressive in its initial outputs, signals the beginning of a journey rather than its culmination. There’s a rich array of techniques we could employ to enhance our system, from base prompt engineering and reranking to chunk optimization and other innovative methods. In future versions, we plan to integrate some of these techniques and additionally offer the TorQ codebase, along with relevant StackOverflow threads about TorQ, as additional knowledge sources. Whilst there’s undoubtedly room for improvement and development, I hope that this example provides a valuable glimpse into the potential of RAG and KDB.AI.
Share this:
















