Low latency struct validation (safe struct)
Data Intellect
Validating Struct Data in Real-Time Systems Using Modern C++
I attended a C++ Belfast meeting, where we explored the peculiar topic – cheap, or even cost free validation of real-time struct data. The topic had been sitting in my to-do list, since I closely work on low latency market data as my daily job.
In latency-sensitive systems, it’s often crucial to validate incoming message structures as quickly as possible to ensure they conform to expectations. Indeed in the vibrant work environment we usually have limited resources to fully test struct data members as we implement required changes. Performing cost-free (or at least cheap) real-time validation would be hugely beneficial and should not be underestimated. So I decided to investigate the proposal in greater depth and determine whether this approach would be beneficial.
This blog will explore in depth the topic covered by C++ Belfast meetup. Notes of the meetup can be found at here. So please familiarise yourself with them, before proceeding further.
To briefly summarise the notes, ‘safe struct’ proposal suggests using C++20 language features to validate that struct data member values have not been left uninitialised. If any value is missing, the approach results in either a compile-time error, or well-defined runtime exception.
I decided to adapt the topic materials to make them relevant to my work. To do this, we first need to define the data that will be processed by the code under test. The data in this case would represent Market Data (MD), which we will generate locally. A widely used protocol in finance is FIX and while MD is typically transmitted using Simple Binary Encoding (SBE) to ensure efficient data transfer to clients. The idea is straightforward—generate a sufficient amount of SBE data, run it through the tests, and verify whether the approach is suitable.
Code Implementation
The original materials and code samples were incomplete for our testing. I refined the code, filled in the gaps, and arrived at the following.
fake_boost.h provides a basic implementation of flat_set, mimicking Boost’s flat_set feature. This helps bypass the Boost dependency for testing. Since the struct only holds a const char* array of a fixed size, it is expected to be efficient enough.
safe_struct_base.h is a simplified version of the original C++ meetup implementation. The design has been slightly modified, primarily to reduce code size (e.g., preprocessor macros ENUM_LLINT, ENUM_CLASS) and improve debugging (e.g., the ToString member function of Account).
The code has also been adapted to some extent to align with the Google C++ Style Guide
The above implementation should be sufficient for our upcoming test. Now we need to produce SBE MD. To perform this let’s define XML structure: safe_struct.xml
The SBE XML above defines fundamental types for each data member of the ‘Account’ struct, effectively replicating how real-world market data might be represented.
Now we can generate SBE MD using the open source SBE GitHub project
java -Dsbe.generate.ir=true -Dsbe.target.language=Cpp -Dsbe.output.dir=include -Dsbe.errorLog=yes -jar ~/GitHub/simple-binary-encoding/sbe-all/build/libs/sbe-all-1.34.0-SNAPSHOT.jar sbeXml/safe_struct.xmlThe above command produces headers for C++ to use to manipulate SBE (part of CMakeLists.txt). These headers are to be used for writing / reading SBE. Now let’s generate an input to be used for SBE headers produced above. We’ll going to use bash shell features to generate random enough data for testing:
for (( i=0; i<=50000; ++i )); do echo $(( $RANDOM%10000 )),$(( $RANDOM%10000 )),$(( RANDOM%10000 )),`if [[ "$(( $RANDOM%2 ))" == "1" ]]; then echo id_verified; else echo address_verified; fi`,`if [[ "$(( $RANDOM%2 ))" == "1" ]]; then echo "active"; else echo "inactive"; fi`,`for (( i=$(( $RANDOM%3 )); i<5; ++i )); do str=${str}"tag"$i";"; done; echo ${str::-1}`,valid,valid; done >> safe_struct_input_new.csvAfter we generated 50k inputs, we need to parse these using SBE headers produced earlier. Here we provide simple code for parsing: safe_struct_writer.cc and safe_struct_reader.cc
In the provided implementation, I have used common approaches for handling struct member population:
- conv_struct – follows the approach from the C++ meetup, using a parameterised function to populate struct data.
- direct – The most basic implementation, where a struct object is created and populated directly
- designate – utilizes C++20’s designated initializers (link)
Now we need to do some performance testing. Running through the tests using ‘valgrind/callgrind’ approach:
for i in safe_struct conv_struct designate direct; do echo "valgrind --tool=callgrind --dump-instr=yes --collect-jumps=yes ./safe_struct_reader ./safe_struct_output.sbe $i && mv callgrind.out.* callgrind.$i && callgrind_annotate --auto=no --threshold=99.99 callgrind.$i > $i.callgrind" ; done | source /dev/stdin‘–dump-instr’ and ‘–collect-jumps’ options were used for ‘callgrind_differ’ Rust tool – for easier table-like comparison of performance measurements between approaches. More information of usage can be found here
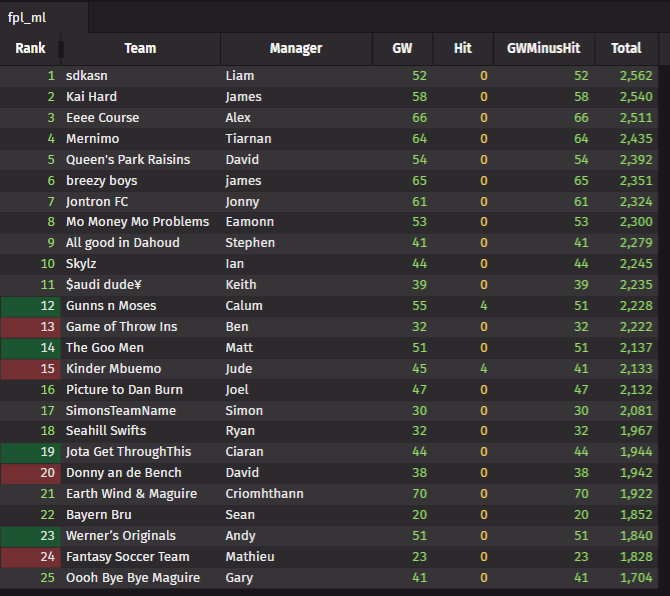
Results

The diagram above shows the combined output from multiple Valgrind runs. The second row indicates that ‘designate’ performs best, running 13% faster than ‘safe_struct’. Red highlights indicate performance losses, while green highlights show performance improvements.
Let’s dive deeper into understanding the output produced by Callgrind. As an initial run, we compare the performance of safe_struct.
The clear winner among the tested approaches is ‘designated/aggregate initialisation.’ Looking at the implementation details, this result makes sense—safe_struct is built on top of basic designated initialisation, so it logically cannot outperform its own underlying approach. Validating the struct adds an overhead of approximately 13%
safe_struct

Designate initializers

The images above present the Valgrind/Callgrind output for ‘safe_struct’ and ‘designated initializers.’ The red rectangle highlights the ‘safe_struct’ section, which represents the overhead implementation that contributes to latency.
As observed in the Callgrind results, validating the struct incurs a performance cost. Although it is declared as constexpr, it is important to note that constexpr serves only as a compiler hint. Since the values are populated from an MD SBE file, they are not known at compile time.
It is good to note, that running ‘safe_struct’ approach with disabled validation also comes with slight cost.
System spec used for testing:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
Model name: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
CPU family: 6
Model: 140
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
Stepping: 1
BogoMIPS: 4838.39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq vmx ssse3 fma cx
16 pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 sme
p bmi2 erms invpcid avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves avx512vbmi umip avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq rdpid
movdiri movdir64b fsrm avx512_vp2intersect md_clear flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Hypervisor vendor: Microsoft
Virtualization type: full
Caches (sum of all):
L1d: 192 KiB (4 instances)
L1i: 128 KiB (4 instances)
L2: 5 MiB (4 instances)
L3: 8 MiB (1 instance)
Vulnerabilities:
Gather data sampling: Unknown: Dependent on hypervisor status
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Reg file data sampling: Not affected
Retbleed: Mitigation; Enhanced IBRS
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS SW sequence; BHI SW loop, KVM SW loop
Srbds: Not affected
Tsx async abort: Not affectedConclusion
The safe struct approach provides a lightweight validation method, making C++ applications slightly safer at cost. However, it is important to consider the additional overhead introduced by validation. In ultra-low-latency applications, where validation is skipped for performance reasons, this approach may not be suitable. That said, validation can be easily disabled by modifying the IsInvalid function, making performance comparable. Additionally, the validation steps are highly flexible and can be adapted to meet specific client requirements.
Limited research has been conducted on the benefits of a pure unit testing approach for detecting newly added fields. Instead, the focus has primarily been on evaluating whether the approach can be applied during real-time data processing.
Share this: