Pulling ahead with Object Pooling
Read time:
10 minutes
Data Intellect
Introduction
In this blog I will delve into the design pattern known as Object Pooling, exploring its impact from a low latency standpoint. I will focus on two versions of Java: Java 8, and Java 21. I will examine pure object creation versus the reuse of objects through pooling. My aims were to gather results by testing two different scenarios, with the goal of discovering if and when to implement object pooling.
Scenarios
The first scenario will center around the use of empty objects, while the second aims to simulate the “real world“ use case by populating the objects in question with real data. This subject matter extends from a testbed project related to the development of a Java based feedhandler, and the subsequent “real data” mentioned will come from a binary file, representing one days worth of market data from New York Stock Exchange (NYSE).
Terminology and Need to Know
Object Pooling
A design pattern used in software development to enhance performance and resource management. The basic idea is to create a pool of reusable objects rather than creating and destroying them on demand.
Message/Message Objects
An object that represents a transaction on the NYSE, with add order, modify order, and delete order being some examples. The object contains data related to each transaction, such as symbol name, order id, and price.
My Collected Data
The data that will be presented below will showcase values representing the time taken in milliseconds to process one million Message objects. Alternatively, these values also denote the average time taken in nanoseconds to process one Message Object, per one million processed Message Objects. It’s worth noting that in these measurements, lower values indicate better performance efficiency.
Percentiles
The values that I will be displaying to show my results will be presented using percentiles. Each percentile that I have calculated indicates the latency times for a portion of the applications run time. As an example, if the calculated 90th percentile shows a latency of one hundred milliseconds, then from that we would know that 90% of the latency measurements gathered took up to one hundred milliseconds each.
The Test Method
When testing, I made sure that code I wrote would match in both test cases (creating a new object, and borrowing an existing object). I would take a timestamp in nanoseconds, and after every million messages, I would take another. I used these timestamps to calculate values, and then gathered percentiles of the aggregate data collected.
The Costs of Objects
I will be covering two types of objects when it comes to costs, Cheap Objects, and Expensive Objects. Cheap Objects are relatively inexpensive to create or initialize, while Expensive Objects come with a higher cost to create or initialize. These costs are in relation to the objects impact on time taken to initialize, and system resources used.
Theory vs. Reality
Empty Object: A term to denote an object that has been created, but does not have data within its internal fields. Use of empty objects will provide a theoretical minimum latency time.
Real Data: A term used to denote that an object has been created, and real data has been populated into the object’s internal fields. Use of objects populated with real data will better represent actual latency times expected to be seen when running against production data.
Object Pooling UML Diagram

Here I have an UML class diagram that represents the Object Pool class that I will be looking to implement as part of this blog post. We can see this pool uses generics, allowing for it to be used with any type of object. For those that would like to try their hand at implementing this without help, skip the next code block, for everyone else please see the provided code block below for my implementation of the very same UML class diagram:
import java.util.ArrayDeque;
public class BasicPool {
private final int poolSize;
private final ArrayDeque pool;
private final Class builder;
public BasicPool(Class type, int poolSize) {
this.builder = type;
this.poolSize = poolSize;
this.pool = new ArrayDeque(poolSize);
}
public final void initializePool() throws Exception {
if (!pool.isEmpty()) {
throw new InstantiationException("Pool already populated: " + pool.size());
}
populatePool(poolSize);
}
private void populatePool(int count) throws Exception {
try {
for (int added = 0; added < count; added++) {
if (!pool.add(createObject())) {
break;
}
}
} catch (Exception e) {
throw new InstantiationException(e.toString());
}
}
private T createObject() throws Exception {
return builder.getDeclaredConstructor().newInstance();
}
public final T borrowObject() throws Exception {
return pool.pollFirst();
}
public void returnObject(T t) throws Exception {
pool.addLast(t);
}
}

To truly know the extent of performance gains achievable from Object Pooling, I first needed to do some testing to gather some data.
I’ve broken my tests into two sections, the first covering empty objects, and the second covering the use of real data to populate the objects in use.
Results For Empty Objects Runs
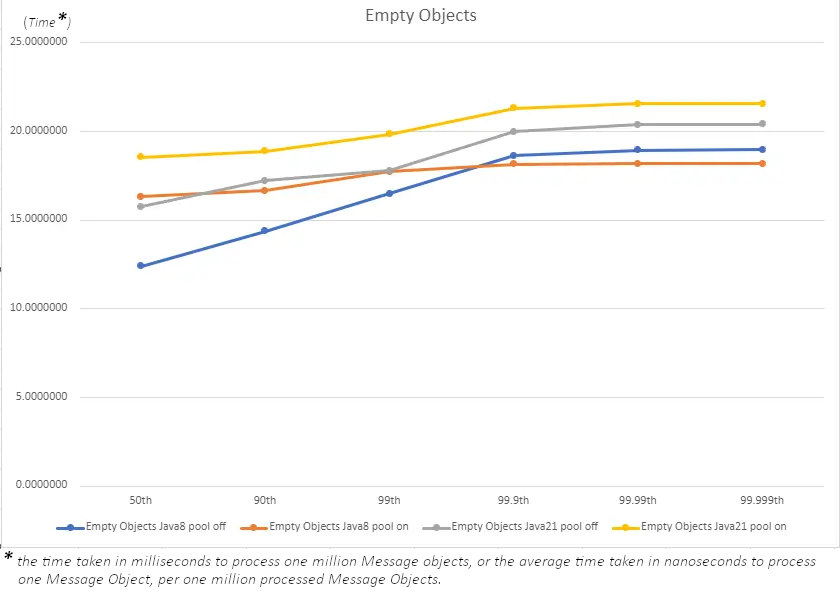
Empty Objects
How Things Compare
-
>
Up to the 99th percentile, the use of pooling seems to lead to higher latency times, indicating a drop in performance across the board.
-
>
In the most extreme cases for the Java 8 runs, a gain in performance becomes visible from the 99.9th percentile. However the latencies are too small to lead to any real performance gains.
Results For Real Data Runs
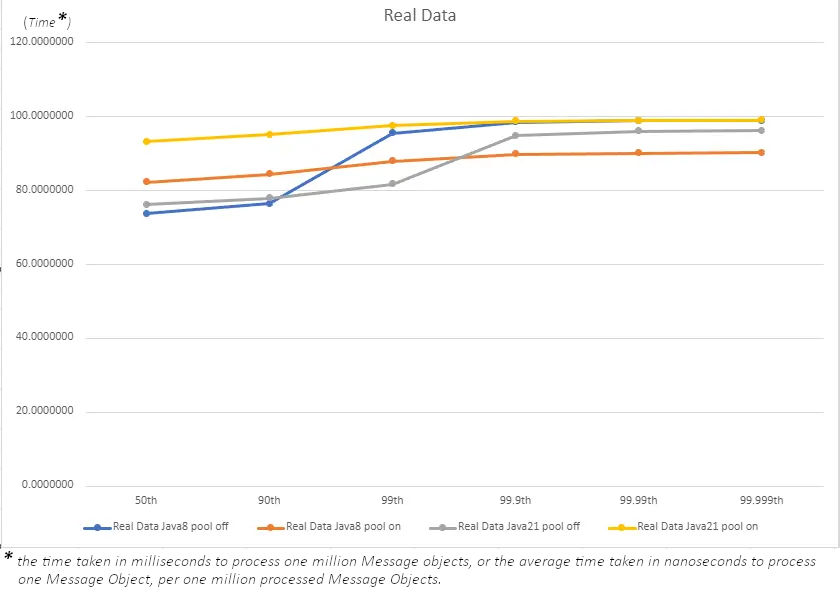
Real Data
How Things Compare
-
>
When we use real data, we also see a very similar situation to the empty objects, where up to the 99th percentile, the use of pooling once again causes latency gains, resulting in a drop in performance across the board.
-
>
Once again the only real gains in performance occur with Java 8, this time from the 99th percentile and up. Similarly to what I stated in the empty object section, this single percentile won’t lead to any real performance gains.
From what I have presented thus far, it would appear that performance gains through Object Pooling were nothing more than a pipe dream… but that doesn’t sit right with me. Lets take a dive into what went wrong, and how we can set things right!
Mistakes and Mishaps – Where I went Wrong
To begin with, we need to have a better understanding of the environment I was working with. When it comes to Message Objects, I had in total twelve different object types, each of which I needed for representing a given transaction that could occur on the NYSE. By extension, this meant I also had to manage twelve Object Pools, leading to extra overhead and unwanted processing when I would call the borrow and return methods. This is due to the fact than I need to manage which pool to borrow from, and thereafter which pool to return to for a given Message Object.
Solutions
So hypothetically, if my biggest issue stems from multiple Object Pools, and having to manage them, I’d need to come up with a solution that would allow for a single Object Pool, while also allowing for the handling of the different NYSE transactions data, If I could do this, then I might see the expected performance gains.
While thinking, I’d remembered something I read when studying up on Object Pooling, specifically that “Object Pooling is best suited for expensive objects, like Database Connections, Pooling Threads, etc.…”. While my Message Objects don’t really compare to those types of expensive objects, it got me thinking, maybe I just need one “expensive” Message Object instead of the current twelve “cheap” Message Objects I had been relying upon. With this, I would only need to manage a single object type, and a single Object Pool, so I gave it a shot.
I modified my code base to use a “combined Message Object” that handles all types of NYSE transactions that I previously handled with the twelve separate Message Objects. This new “combined Message Object” in question is able to do this thanks to it containing all the fields that could be found within the twelve cheap Message Objects, as well as methods that would update the state of the object via a “Message Type” field, and overwrite any fields related to said Message type.
Now with a new implementation that allows for one Message Object, and one Object Pool, I once again performed a round of testing to gather data.
Like before, I’ve broken my tests into two sections, with empty objects, and real data objects.
Results For Empty Objects Runs
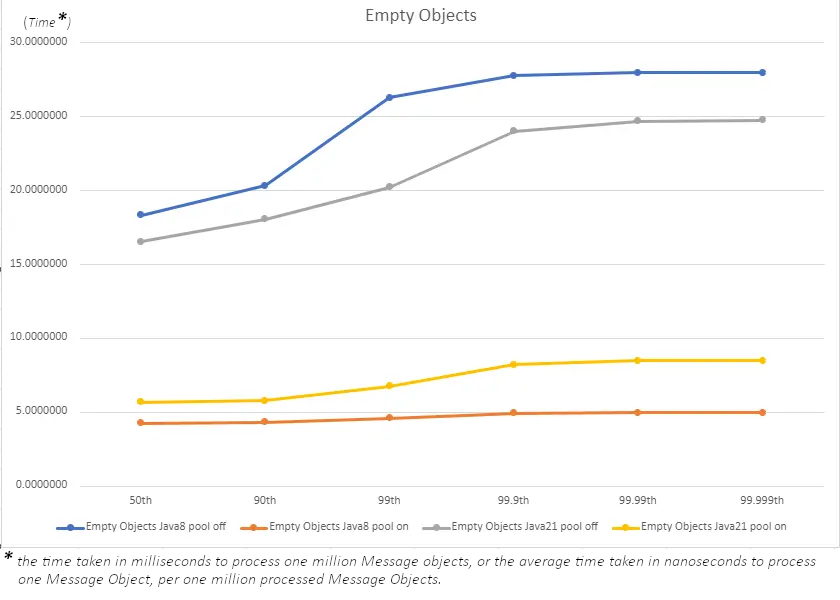
Empty Objects
How Things Compare
-
>
As one might expect, when the pool is not in use, the latency times we see for this new expensive Message Object is higher than it was in the data shown earlier in this blog. However, we also see that across the board how big of an impact Object Pooling is having on both versions of Java.
-
>
Additionally, we can see that with this current implementation method used, it has allowed for Java 8 to go from having the highest latency times, all the way to the lowest latency times! Now of course this test is more theoretical in that it’s using empty objects, so lets move on and find out how things compare when we introduce real data into the picture.
Results For Real Data Runs
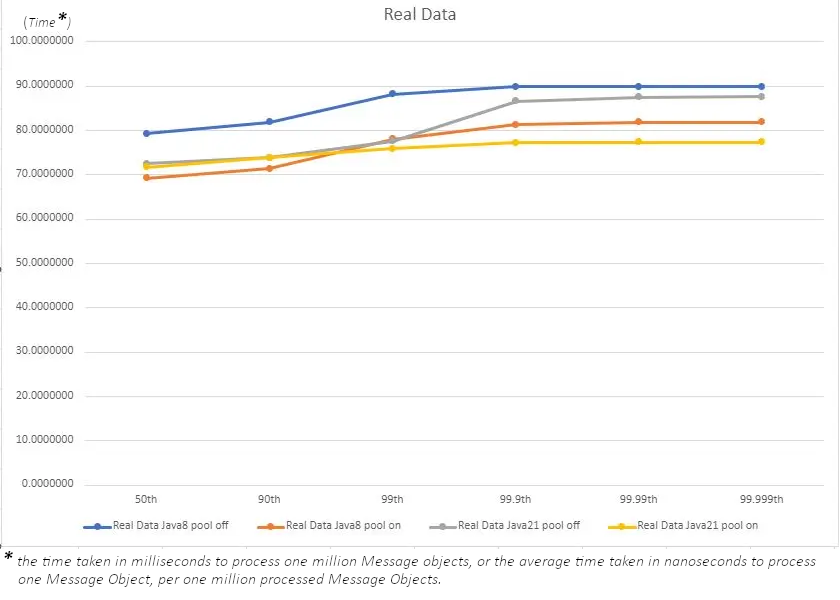
Real Data
How Things Compare
-
>
With the results using real data in hand, we now start to see something interesting. On the Java 8 side, we see Object Pooling in all its glory, showing latency improvement across all percentiles; this is a good indication of improved performance thanks to Object Pooling.
-
>
For the newer Java 21, things seem to be taking a different route, with percentiles up to the 99th almost matching from a latency standpoint. Only in the most extreme cases of 99.9th percentiles and up do we see object pooling have any form of impact.
Why we don't see the same gains in Java 21?
Java 21 is much newer, and has over time been improved with optimizations from a code and compilation perspective. There is also an improved Garbage Collector which is capable of handling the Garbage Collection process much more effectively, reducing pause times overall, thus helping to improve latency times.
An accumulation of all of these improvements allows for Java 21 to perform just as well 99% of the time, and is a good indicator for maybe switching to a newer version of Java before taking a look at other performance improvement.
Conclusion
What do we learn from all of this? First, if we are looking into using Object Pooling, the code base needs to be reviewed to ensure it is fit for purpose. We should try to avoid using Object Pooling if we are looking at a code base that would require extra overhead from the managing of a number of different objects across several object pools.
Second, it’s important to perform necessary testing to gather statistics on latency times before and after implementing Object Pooling, or before and after modifying the code base to work with Object Pooling, as the statistics will paint a clearer picture on the impact of any changes made, and guide you down the right path.
Third, if we are using an older version of Java like Java 8, then implementing the Object Pooling Design Pattern into a code base is a must (given the correct code base). In cases where upgrading to a later version of Java is not available, the improved latency is huge win in my books.
Finally, when using the later versions of Java, such as Java 21, Object Pooling might only help you out in a very small percentile of your overall latency time. Of course there are still benefits in that it helps create more predictable latency times, and helps to prevent the small number of latency jumps, which would be beneficial in low latency situations.
Extra Notes
My Queue Selection
For my Object Pooling implementation, I have run tests using a number of different types of “Queue” implementations, and found that using an “ArrayDeque” object to hold the pool of objects provided the best results in my case. That doesn’t mean this will be the same for you, always remember to experiment to ensure the same applies for your use case. Additionally, using an ArrayDeque means that my implementation is not thread safe, so in cases where that is an important factor, maybe have a look at an alternative queue implementation.
An Unstated Issue
One issue I dealt with when creating the pool was I didn’t limit the pool size, and also allowed for the “borrowObject()“ method to create new objects if the pool is empty, to test self balancing. However I made the mistake in the same method, which led to my implementation only creating new objects. This led to the pool growing in size, and while things looked fine for part of the run time, eventually the pool grew in size and caused crashes. This could easily be missed if one does not test properly, using a large data set, as in my case I didn’t notice the issue until I ran through using 10 million+ messages.
Memory Leaks
Lastly I feel it is important to mention when it comes to the use of Object Pooling, you can also run the risk of memory leaks. To avoid memory leaks with Object Pooling, make sure to:
Properly return objects to the pool: Always return objects to the pool when they are no longer needed. This ensures that the resources associated with the objects are released.
Reset object state: If an object has internal state or references, make sure to reset or clear them before returning the object to the pool. This ensures that the object is in a clean state when reused.
Handle exceptions: If an exception occurs while an object is in use, it should not prevent the object from being returned to the pool. Implement proper exception handling to ensure that objects are always returned, even in the case of errors.
Share this: