Paul McVicker
On paper, intelligence has a simple definition; it is the ability to acquire and apply knowledge and skills. However, we tend to ascribe a significantly higher meaning to this word, often because we use our own brains to perform incredibly intelligent tasks every day without much thought.
One of these tasks is the recognition of objects. Being able to see an object or an image and being able to recognise what it is seems simple to us, but it is the result of the incredibly complex neural networks in our brains and a lifetime of learning that allows us to do this.
The following blog will discuss the use of Artificial Neural Networks to classify images, and the benefits of using KDB.AI as an extra layer on top of these networks by testing its abilities at detecting various sugarcane diseases from images of sugarcane leaves.
Artificial Neural Networks and Transfer Learning
Artificial Neural Networks are a form of deep learning, a subset of machine learning which aims to emulate the neural structure of the human brain. The network takes in data, trains itself to recognise the patterns in the data, and then is able to make predictions on what similar data might be based on these patterns.
In the case of image search, the image is broken down into individual pixels and each pixel is fed as input to the neural network. Each pixel is then assigned a numerical value based on certain factors, such as the colour of the pixel, and then is passed onto the next layer, or ‘neuron’. At each layer, new weightings are assigned, and calculations are performed, which will ultimately produce a number value that corresponds to the inputs which will then be referenced when the network is used to classify other images.
Much like the human brain, this network is incredibly complex, and so creating a new network from scratch is incredibly difficult and impractical. To get around this, we use transfer learning.
Transfer Learning is the process by which an existing Artificial Neural Network is trained on a new dataset, and then a model is created based on this training that can be used to accurately classify similar data.
In relation to how the human brain works, an example of this would be a doctor looking at an MRI scan of a patient with a brain tumor. A trained doctor will be able to look at a scan and determine the type of tumor present, whereas the average person who is untrained will not be able to differentiate between one type of tumor and the next. This is because the doctor will have spent time learning about and working with these scans and will be able to instinctively spot the differences that an untrained person will not. This is what we aim to replicate with transfer learning.
Why use KDB.AI?
If you are unfamiliar with KDB.AI, I suggest you read the previous blogs in this series, entitled; TESS: The AI Journey Begins, Exploring Anomaly Detection with KDB.AI, and Market Data Magic, with KDB.AI. For the scope of this blog, it is important to know that KDB.AI is a scalable vector database that can be used to store vector embeddings for your chosen dataset.
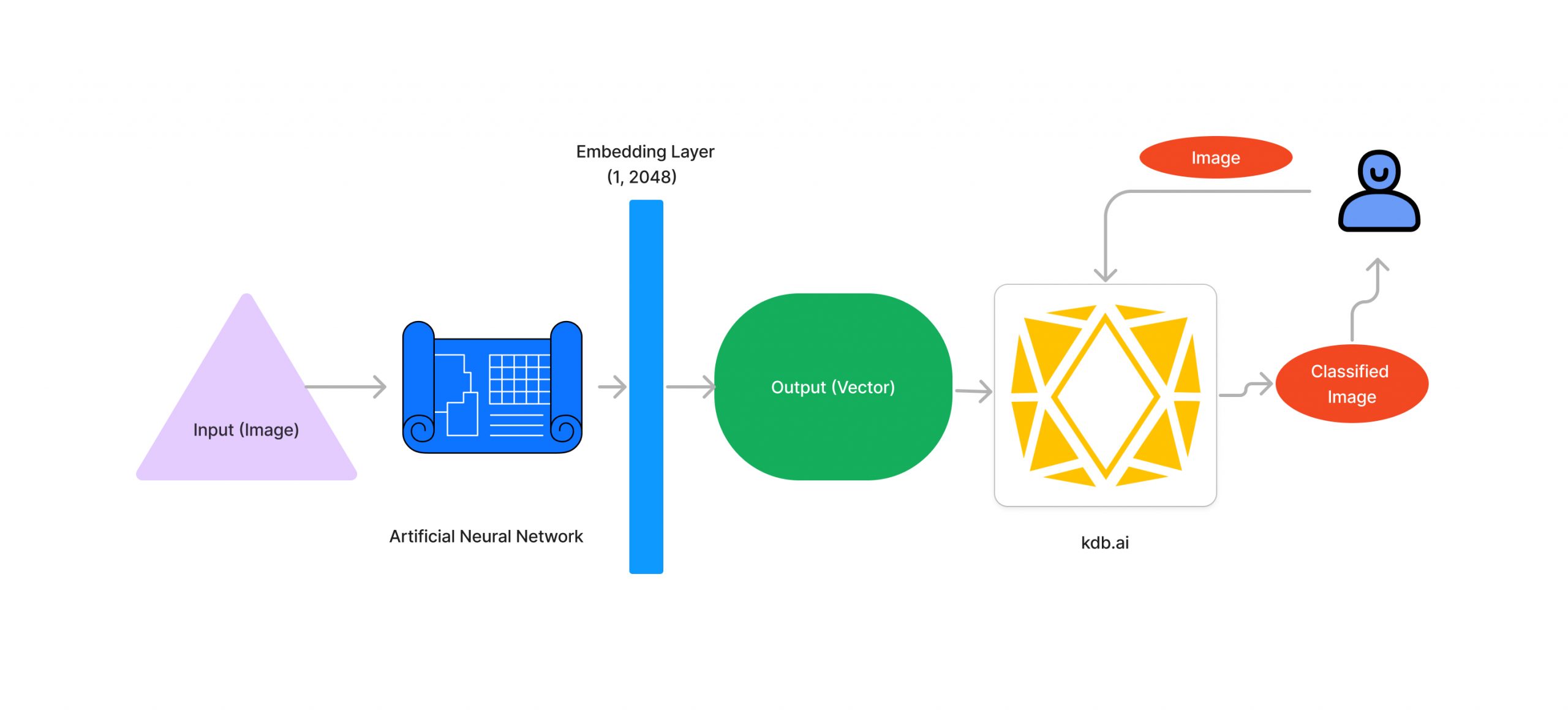
The benefit of using KDB.AI for image search applications is the ability to access and view similar images to the image you are looking to classify. For each image, the neural network will classify the content and generate a vector embedding, which captures key information about the image. These embeddings can then be stored in the KDB.AI database. This differs from the use cases demonstrated previously, as there is no need for an external embedding model. By storing the classified images in KDB.AI, the information from the trained neural network can be referenced in later analyses.
The storing of image data in the form of embeddings allows for a human observer to see similar images to what they are intending to classify. This can be beneficial, as it gives the observer more information than just a simple classification provided to them. Another benefit is that classification of the images can be done by comparing them to similar images, which, as will be discussed later in this blog, can lead to increased classification accuracy.
Another benefit alongside the increased accuracy is the scalability of the model. Performing transfer learning on a neural network is very costly, both in terms of time and computational power. If we want to create a more rigorous model, we would have to retrain the network on an even larger dataset, consuming even more time than the original dataset. With KDB.AI, the embeddings of already classified images can be inserted into the table, increasing the amount of data to be referred to with a fraction of the time and computing power.
This can also be done in tandem with the classification of new images, as once the image has been classified, it can also have its embeddings inserted into KDB.AI, further expanding the database.
Putting it into practice
To test the benefits of using KDB.AI, a sugarcane disease image dataset was used to test the accuracy of various neural networks for image classification. This dataset was chosen for its size of 2521 images and 5 classifications; healthy, mosaic, redrot, rust and yellow. 2521 is a large enough dataset to produce respectable results but not too large that it becomes impractical to develop classification models using it.
18 different neural networks that are supported by the Keras module on Python were trained using this data set, and a measure of the best accuracy was found by testing a subset of these images. The resulting classification accuracies ranged from RegNetX064 and ResNetRS50 with best accuracies of 78.21% to Inception ResNetV2 with a best accuracy of 32.68%
These findings demonstrate that each neural network has its own strengths and weaknesses, and some networks are more suitable for use in this case than others. The networks chosen to combine with KDB.AI were EfficientNetB7, EfficientNetV2B3, RegNetX064, RegNetY064, ResNet50 and ResnetRS50.
The differences in model performance presented here have important implications for the image analysis. The neural network is used to create 2048-dimensional vector embeddings for each image supplied to it, which are then stored in KDB.AI. When an accurate neural network is used, it can create embeddings that reflect the differences and similarities between images that will allow them to be used for classification. When a less accurate neural network is used, the embeddings do not reflect the differences and similarities between images. This can be seen through the 2-dimensional representations of the vector embeddings created for this data set shown below:
RegNetX064
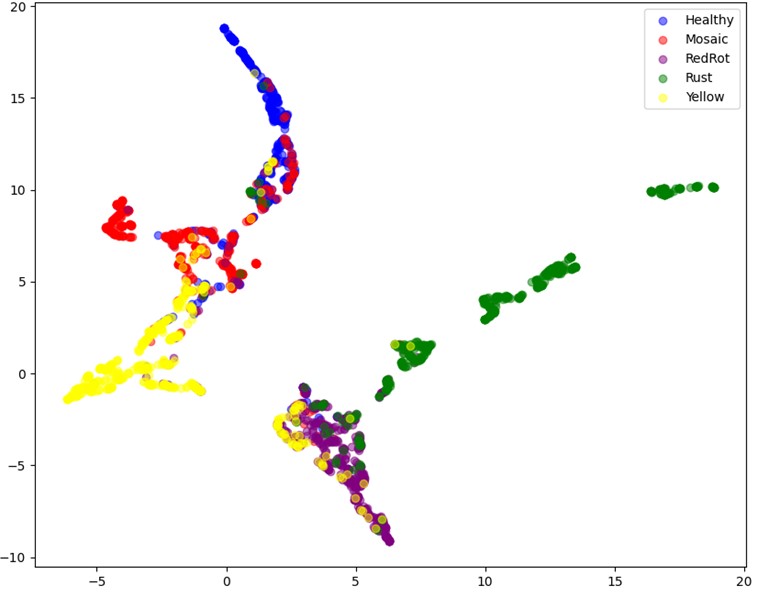
As can be seen on the right, the embeddings created by RegNetX064, a network with a best accuracy of 78.21%, produce a graph with well-defined regions for each classification and has limited crossover between each classification.
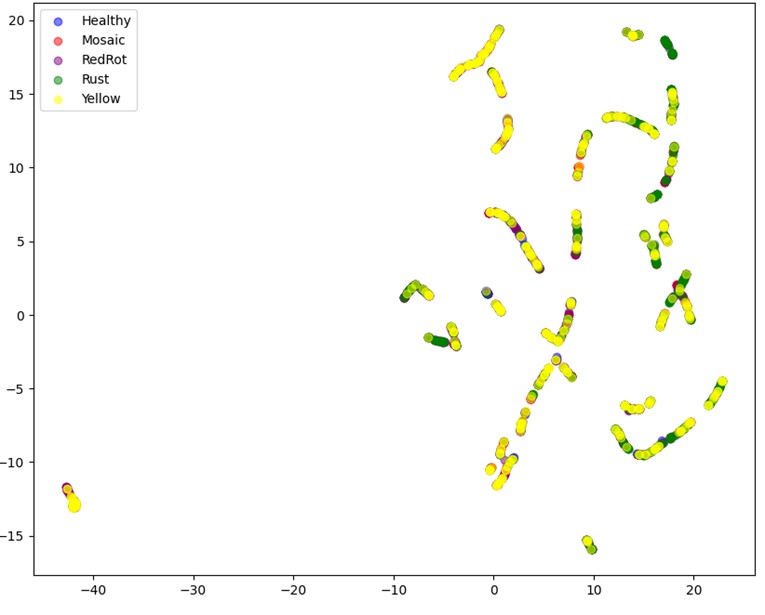
Inception ResNetV2
In sharp contrast to RegNetX064, the embeddings created with Inception ResNetV2, with a 32.68% accuracy, produce a graph that does not have clearly defined regions and has significant crossover between each classification.
These models were then used to create embeddings for the images it had been trained on, and then these embeddings were stored in KDB.AI. Following this, similar classifications were created for the test data using the same model. These classifications could then be tested against the embeddings in KDB.AI using the following function:
table.search([x], n=y, index_options={'efSearch': z}) In this function, x is the embedding, y is the number of results to be returned and z is the number of nearest neighbors to be searched, in this case based on Euclidean Distance between the vectors.
The test images were then classified based on the most common classification amongst its neighbors. The best accuracy for each network was then calculated by finding the most accurate search length for each network, ranging from RegNetX064, with a best search length of 7 to RegNetY064 with a best search length of 142.
The following table shows the best accuracy for each network both with and without the use of KDB.AI, and the difference between them:
| Neural Network | Best Accuracy without KDB.AI / % | Best Accuracy with KDB.AI / % | Difference / % |
| EfficientNetB7 | 72.37 | 72.00 | -0.37 |
| EfficientNetV2B3 | 70.04 | 74.04 | +4.00 |
| RegNetX064 | 78.21 | 81.60 | +3.39 |
| RegNetY065 | 72.37 | 75.20 | +2.83 |
| ResNet50 | 76.65 | 71.20 | -5.45 |
| ResNetRS50 | 78.21 | 77.60 | -0.61 |
Conclusion
Through the previous demonstration, we were able to take the existing methodology of using an Artificial Neural Network and expanded upon it by converting these networks into embedding networks and storing the resulting data in KDB.AI. This has led to a more practical method of performing image search that is scalable and more time efficient than previously devised methods.
Despite its inclusion leading to varying differences in accuracy depending on which Neural Network is used, the ability to compare images with others in a database can be very helpful for a human observer and can contribute to anomaly detection that would be left unchecked had just the Artificial Neural Network been used.
It should also be noted that throughout this case study, the best accuracy overall was 81.6%, which was achieved by using RegNetX064 alongside KDB.AI. Due to this, KDB.AI should always be tested and considered for use with any image classification model you may like to develop, as it has proven that it can lead to more accurate results than just using an Artificial Neural Network on its own, and offers significantly more flexibility when expanding the model.
Continue to follow this blog series for future updates regarding KDB.AI, its various applications, and its benefits.
Share this: