Data Intellect
Introduction
Welcome back to our ongoing series delving into the myriad applications of KX’s vector database, KDB.AI. In this edition, we’re thrilled to unveil the enhancements made to our prototype TorQ support bot, TESS, introduced in our previous blog. These upgrades include Multi-chunking, Re-ranking, Conversational Awareness, Prompt Engineering, and Personalised Dynamic Loading.
The methodologies and advancements detailed herein aren’t confined solely to TESS but extend to all chatbots built on the RAG framework, leveraging LangChain and vector databases. Given the limited understanding of kdb+ and TorQ by mainstream large language models, these upgrades represent a major step towards automated kdb+ assistance.
To understand some of these upgrades it is important to mention some background information on vector embedding. A basic vector embedding of a document consists of splitting the document up into chunks, embedding these chunks as vectors, and storing these within a vector database. Then when supplied a query, the RAG system uses a retriever model to search the vector database for relevant chunks, which are then passed along with the prompt to a large language model (LLM) to generate a coherent and appropriate response. Understanding how our data is being embedded will enable us to refine our methods of searching the database by optimizing the alignment between search queries and the underlying structure of the embedded content.
When we embed text chunks as vectors, similar chunks will have similar vectors. This allows us to measure the similarity of chunks by taking the distance between their vectors. Note how in the 2D representation the fruit, pets, and vector database follow this logic based on their proximity to each other.
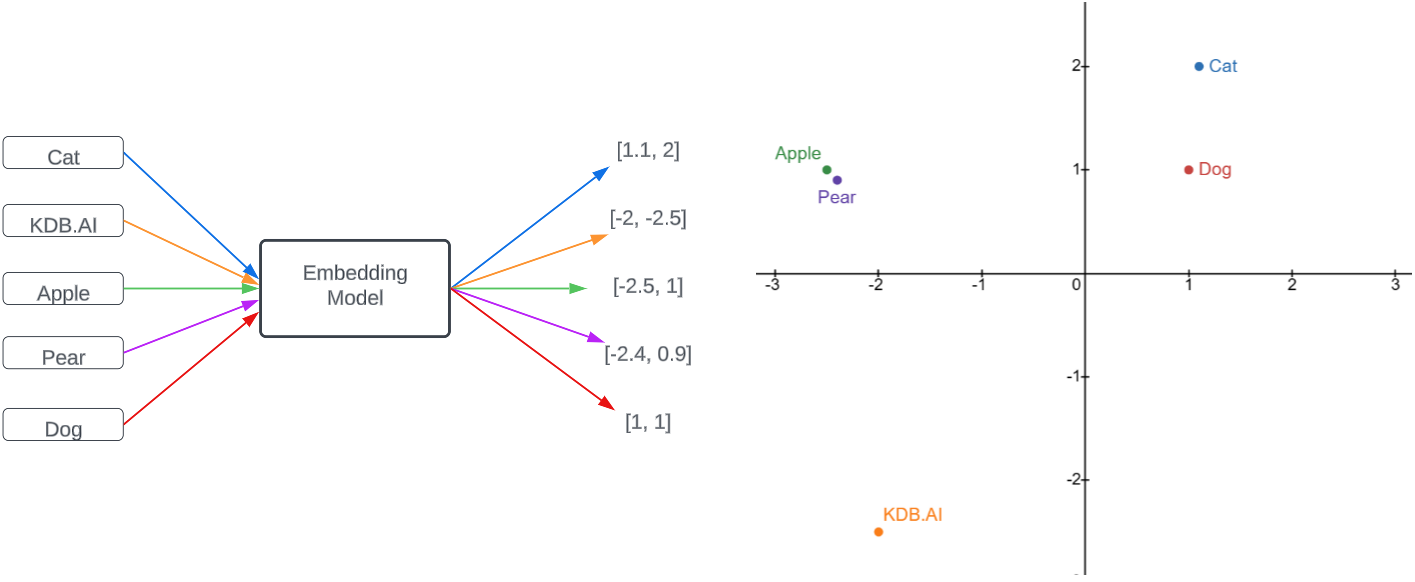
The same principle applies when we embed larger chunks such as sentences or paragraphs. Therefore, in order to optimise the data retrieval process, we must make sure the data we want is accessible within the database, and that our query best matches this data.
In particular, we want a chunking strategy which best captures all the different concepts and ideas within our documentation as vectors so that we retrieve the most relevant data. We also want to craft queries that best match these relevant chunks.
Multi-chunking
In our previous blog we specified only one chunk size and overlap size when splitting up the document. This approach performed well, however there were some definitions and instructions that ran over the specified character count and were then split over multiple chunks making them more difficult to search for within the database. So how should we chunk our data?
On one hand, small chunks will struggle to efficiently capture more complex concepts that require additional context. On the other hand, large chunks risk concepts being watered down or lost in the sauce – too large a chunk could muddle an idea and weigh it down with unnecessary extras to the point that the original succinct meaning isn’t used in the response. As a result, different questions will gain their best response with different chunking. For this reason, no single chunk size will be optimal.
This presents a bit of a problem because we don’t know the question before it is asked, so what is the best path forward? One method is to take the question, start with an initial chunking variant, query it and repeat for many various chunk styles and then select the best result given. However, this approach tends to be more time-consuming and costly, and can result in overlapping hallucinations.
The option that we opted for is what we call ‘Multi-Chunking’. One of the main benefits of KDB.AI is that it’s able to generate, store and access large vector databases quickly and easily. So rather than chunking in response to a query, we take the material and create many different chunk variants and build up a large vector store. Then when a query is called, we pull the best options we have in our vector database, process and return the answer. This gives us the benefit of using various chunkings without having to invoke the LLM repeatedly. Additionally, we further improve this process by using a re-ranker which allows us to pull better data from our vector database.
Re-ranking
Re-ranking data is a common technique in RAG frameworks because it has low costs and strong improvements. It’s a process wherein the data being pulled for a query is re-ranked by a different system for its relevance.
Initially when you have a query, you will pull relevant data using one of your standard processes such as similarity searches. However, the most relevant query is not necessarily the best result. Thus, when we have a re-ranker, what we tend to do is pull a number of queries and then re-rank those queries with a different process with the idea being that the best results for both will rise to the top and then those results are used in the RAG framework. This secondary process is often done with an AI model such as Cohere which has specialised training for this purpose.
However, because this re-ranking process can only occur after a query has been given, it adds to the users wait time because it cannot be done as part of system setup like multi-chunking can for example. Thus, re-ranking needs to be both effective and lightweight in order to be justifiable in most cases. Thankfully, much work has been done to improve both of these measures resulting in re-ranking being one of the most effective improvements that one can add to a RAG system.
The code for our re-ranker is shown below.
documents = TextLoader(
"./TorQ+Conf.txt",
).load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
for idx, text in enumerate(texts):
text.metadata["id"] = idx
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = FAISS.from_documents(texts, embedding).as_retriever(search_kwargs={"k": 20})
llm = ChatOpenAI(temperature=0)
compressor = FlashrankRerank()
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)Conversational Awareness
Popular AI chat bots such as Chat GPT are so intuitive to use due to their conversational nature. Instead of navigating through menus or interfaces for information, users can explore topics through directed natural language discussions providing quick and convenient access to the desired information. This functionality is particularly useful in support settings where users may not understand the problem they are dealing with.
Below we describe how to outfit a RAG chatbot such as TESS with basic conversational awareness by adding a chat history feature.
As this is a basic implementation of chat history, we will save the conversation along with any system messages in a list.
from langchain.schema import (
SystemMessage,
HumanMessage,
AIMessage
)
messages = [
SystemMessage(content="You are a TorQ Expert Smart Support bot called 'TESS'."),
SystemMessage(content="Interpret the following acronyms when answering questions. RDB is an acronym for real time database, WDB is an acronym for write database, CTP is an acronym for chained tickerplant, STP is an acronym for segmented tickerplant, TP is an acronym for tickerplant, and HDB is an acronym for historical database."),
]The conversation can now be stored, but how do we get TESS to use this information?
When we give TESS a query, it is vector embedded and the vector database is searched for chunks semantically similar to the query. The LLM then uses these chunks to construct an appropriate and accurate response. Most LLM’s today have a level of conversational awareness, however the LLM is only responsible for forming the responses. The data retrieval is handled by the RAG framework which is not conversationally aware. Therefore, we wish to have the RAG framework take the chat history into consideration when searching the vector database.
When using RAG, it is best practice to make your queries clear and concise as this ensures accurate similarity matching while using less tokens. For these reasons, embedding the entire chat history along with the query is inefficient and expensive. Similarly, embedding relevant subsets of the chat history with the query will retrieve chunks that are predominantly similar to the past conversation and not the new query specifically, leading to less accurate results.
A solution here is to use the LLM to reform the query using the chat history into a standalone question. This allows us to engineer a clear prompt which considers chat history.
We optimize outcomes by providing the LLM with only the pertinent elements of the conversation, in our case the initial system messages and Tess’s latest response.
chat = ChatOpenAI(model='gpt-3.5-turbo-16k', temperature=0.0)
def rel_info(msgs):
if len(msgs) > 3:
return msgs[:2], msgs[-1]
else:
return msgs
def contextualise_query(query: str):
contextualize_q_system_prompt = f"""If it seems like a user asks about something related to the Chat History
Given the following conversation and a follow up question,
REPHRASE ONLY the follow up question to be a clear concise question that can be understood without context
based on the conversation.
Chat History:
{rel_info(messages)}
Follow up question:
{query}"""
return chat.invoke(contextualize_q_system_prompt)Now we can create a function wrapping contextualise_query in with the bot as well as saving the chat history for each query.
K = 10
qabot = RetrievalQA.from_chain_type(chain_type='stuff',
llm=ChatOpenAI(model='gpt-3.5-turbo-16k', temperature=0.0),
retriever=vecdb_kdbai.as_retriever(search_kwargs=dict(k=K)),
return_source_documents=True)
def TESS_2(query):
query = contextualise_query(query).content
messages.extend([HumanMessage(content=query)])
print(f'\n\n{query}\n')
messages.extend([AIMessage(content=qabot.invoke(dict(query=query))['result'])])
print(messages[-1].content)Prompt Engineering
When reforming queries for RAG chatbots, it’s natural to consider prompt engineering to optimize responsiveness and accuracy by tailoring prompts.
Carefully crafted prompts can guide the LLM towards creating more accurate responses that align with the conversation’s flow and topic, while mitigating any biases the model may have. Finding the best way to phrase a query can be an expensive and tedious process, usually involving a lot of trial and error. Ideally, you would engineer the prompt for the semantic search and LLM separately, finding the best prompt in each case. However, as our bot performs both processes consecutively, our prompt must be a one size fits all solution that produces the best response overall.
Creating such a prompt depends greatly on the embedded information in the vector database. In our case, the vector database contains documentation detailing definitions, instructions, and even snippets of code associated to specific tasks relating to TorQ. Hence, it is important to mention what form you wish the response to take, whether that be a detailed explanation, some lines of code, or both.
As we are trying to automate this process without making another API call to the LLM, it is important to only hardcode additions that are not query specific. With this in mind, I have modified the contextualise_query function from before to carry out some simple prompt engineering that proved beneficial for TESS.
def contextualise_query(query: str):
contextualize_q_system_prompt = f"""If it seems like a user asks about something related to the Chat History
Given the following conversation and a follow up question,
REPHRASE ONLY the follow up question to be a clear concise question that can be understood without context
based on the conversation.
Rewrite 'RDB' with 'real time database',
Rewrite 'HDB' with 'historical database',
Rewrite 'WDB' with 'write database',
Rewrite 'STP' with 'segmented tickerplant',
Rewrite 'CTP' with 'chained tickerplant'.
If "in TorQ" is not mentioned in the question .
After the question write 'Explain fully.'.
Chat History:
{rel_info(messages)}
Follow up question:
{query}"""
return chat.invoke(contextualize_q_system_prompt)Personalised Dynamic Loading
When querying TESS for answers, users often want code to execute which TESS is usually able to give. However, this code can be dependent on the user’s configuration – the user’s file path, their hostname, what their tables/columns are called etc. As such, without additional information, TESS normally could only give a generic answer and ask the user to make the replacements themselves. This can be bothersome for users because it’s asking them to do additional work and depends on users knowing what to substitute. This second issue can be particularly problematic for complex setups and users who have limited knowledge of navigating their system.
With this version of dynamic loading, we have the user’s personalised settings on an additional text file (although a better version without a text file intermediary can be made with PyKX). This file is then vectorised and added to the vector database and made available for use by TESS. This allows TESS to make the code substitutions herself rather than leaving it as an exercise for the user. This is particularly useful for certain commands as the user might not be aware of their personal settings immediately such as file-paths or port numbers. Additionally, even if the substitution is quick and easy for the user, it’s often just a better experience to not have to bother with it. We improve the availability and use of the personalised data through prompt engineering where we ask that where possible, code should have substitutions using the personal settings.
This feature will hopefully be developed where the file being loaded in will also have additional details such as what tables/variables are in memory. However, such a project requires a way to connect your KDB data with the python based TESS. Thankfully, such a connection exists through PyKX (insert link to PyKX project). For the mean time we are asking TESS to make substitutions using the personal settings as part of the prompt.
Results
Below we will compare the results of TESS 1.0 against TESS 2.0, with functions TESS_1 and TESS_2 respectively.
TESS_1("How do I replay a TP log file?")How do I replay a TP log file? To replay a TP log file, you can use the ticker plant's replay functionality. The exact steps may vary depending on the specific implementation of the ticker plant you are using, but generally, you would follow these steps: 1. Stop the ticker plant if it is currently running. 2. Locate the log file that you want to replay. 3. Configure the ticker plant to replay the log file. This can typically be done by specifying the log file path and any other relevant parameters in the ticker plant's configuration file. 4. Start the ticker plant, specifying the replay mode. 5. The ticker plant will read the log file and publish the records to the real-time processes or subscribers. It's important to note that the exact details of how to configure and start the ticker plant in replay mode may vary depending on the specific implementation you are using. It is recommended to refer to the documentation or user manual of your ticker plant implementation for more specific instructions.
TESS_2("How do I replay a TP log file?")How do I replay a TP log file in TorQ? Explain fully.
To replay a TP log file, you can use the tickerplant log replay process in TorQ. Here is an example command to replay a log file:
q torq.q -debug -load code/processes/tickerlogreplay.q -p [portnumber] -.replay.tplogdir [tickerplant log files or directory] -.replay.schemafile [file defining table schema] -.replay.hdbdir [database directory]
Replace [portnumber] with the desired port number for the process. Replace [tickerplant log file or directory] with the path to the log file or directory containing multiple log files. Replace [file defining table schema] with the path to the file that defines the table schema. Replace [database directory] with the path to the directory where the replayed data will be stored.
Here is an example command:
q torq.q -debug -load code/processes/tickerlogreplay.q -p 52810 -.replay.tplogdir ../../../data/tplogs/stp1_2023.02.13 -.replay.schemafile ${TORQAPPHOME}/database.q -.replay.hdbdir ../../../data/testdir
Make sure to adjust the paths and port number according to your setup.
TESS_1("What code do I use to query my quote table for Google and IBM quotes between last week and today in TorQ?")What code do I use to query my quote table for Google and IBM quotes between last week and today in TorQ? To query your quote table for Google and IBM quotes between last week and today in TorQ, you can use the following code: ```q select from quotes where sym in `GOOG`IBM, date within .z.d-7 0N ``` This code will select the quotes from the "quotes" table where the symbol is either "GOOG" or "IBM" and the date is within the last week (from 7 days ago until today).
TESS_2("What code do I use to query my quote table for Google and IBM quotes between last week and today in TorQ? Please make substitutions using my personal settings.")What code do I use to query my quote table for Google and IBM quotes between last week and today in TorQ? Please make substitutions using my personal settings. To query your quote table for Google and IBM quotes between last week and today in TorQ, you can use the following code: ``` select from QuoteBoat where sym in `GOOG`IBM, date within (.z.d-7; .z.d) ``` This code will select the quotes from the "QuoteBoat" table where the symbol is either "GOOG" or "IBM" and the date is within the last week (from 7 days ago until today).
It is important to note here that TESS_2 has made use of this users personal settings file where they have specified the name of their quote table and how to format weeks.
Costs
It’s safe to say these features have improved the quality of TESS’s responses, but at what cost?
When implementing these features initially it can take some time to optimise the additional data being provided to the bot. For the best results one should continue to adjust their prompt settings, chunkings, and chat history features until they are getting satisfactory responses. In particular, with any prompt engineering it is crucial to explore which methods incur the least hallucinations from the LLM. Fortunately, there are a number of tools being developed currently such as HILL (Hallucination Identifier for Large Language Models) which identify where AI has hallucinated connections where none exist. Integrating these sorts of tools will potentially increase the runtime required but should notably improve accuracy by flagging hallucinations.
Each of the features discussed today involve LLM API calls, which depending on the query can consume over a hundred thousand tokens, exceeding most free LLM API rate limits. It is important to consider the true value of these features with respect to ones budget.
While not important for TESS due to the lack of confidential material, it’s worth mentioning the security of these features. Unless you run your own AI model, the data you send to the AI will be available to the owners and whomever they pass data to. As such, unaltered proprietary information such as ones personal settings and passwords are at risk when interacting with an AI. To alleviate some of these issues, several methods can be explored to protect our data when dealing with LLMs. One such method is Layerup, designed to sanitize LLM interactions to minimize exposure to proprietary data and mitigate prompt injection attacks. Layerup boasts model agnosticism, making it adaptable to various models. Unfortunately, its additional layering can significantly extend runtime.
Conclusion
In conclusion, the strides in enhancing TESS’s capabilities underscore the invaluable contribution of vector databases like KDB.AI in elevating our AI interactions. In future versions, we plan to improve on these features, introduce new features such as source citing and layerup security, and use tools such as Langsmith to manage these features. With ongoing development and the rapid evolution of technology, KDB.AI continues to introduce innovative features such as Multi-Modal RAG and Time Similarity Search, alongside integration with tools like LlamaIndex. This trajectory indicates that RAG chatbots like TESS are poised to play a pivotal role in the future of tech support, promising an even more enriched user experience ahead.
Share this:
















