Read time:
4 minutes
Gary Davies
You get a connection, you get a connection, you get a connection.....

When kdb+ 4.1 got its production release recently I remember thinking, “jackpot” no more limits on the connections for IPC/Websockets, and my mind shifted to the Oprah Winfrey meme (hopefully you get that “connection”).
I’m sure our regular readers or anyone that follows me on LinkedIn has heard me rattle on about the need to do architecture reviews, and with new versions being released its worth putting that hat on:
– what does this mean for those in-situ systems?
– and are there lessons to consider when going greenfield?
So I sat down and started reflecting on scenarios where I’ve been involved in discussions about the connection limit – surprisingly I had 2 realizations;
1. discussions/actions always came after the ‘conn error appearing
2. approximately 50% of the time it was “a bug”
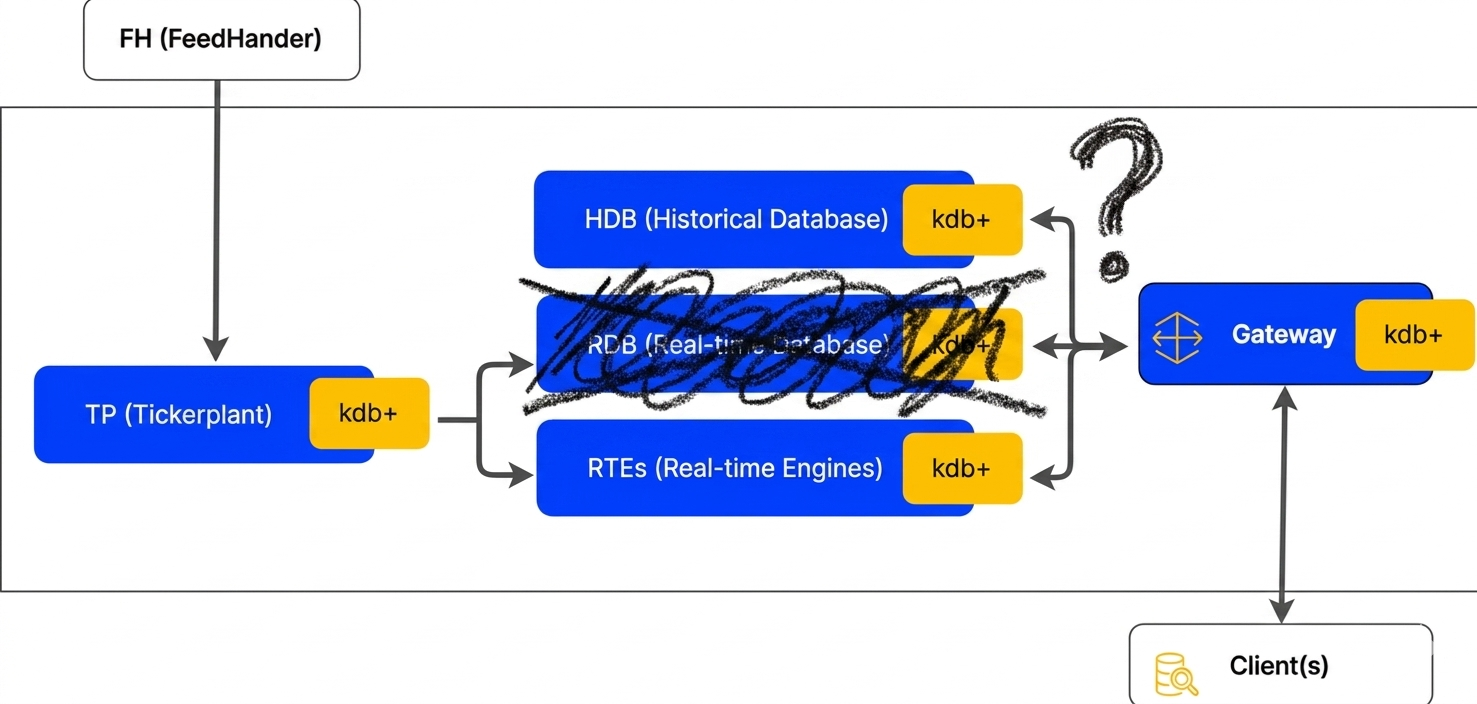
Realistically we don’t want to be having discussions after the ‘conn, as by that point the capacity of the system is likely exceeded and up until now usually required a slight re-architecture. Realistically systems sub-4.1 you want to be thinking about connection numbers and capacity planning around that.
The second realization however is what brought me to writing this blog……..
Staying Connected
Ok so firstly, lets look at when its been a needed feature.
Its been a recurring topic for me over the years, and either revolves around large interconnected systems or large numbers of users. As architects and developers we adapted to this limit creating our own means of scaling via secondaries or splitting up processes to achieve what we needed. This usually adds unnecessary complexity to the systems and while it can be good fun to work to solve it’s not quite as simple as just allowing the connections like we can in 4.1. I already know of a few of our clients who could simplify architecture and functionality off the back of the changes, and these simplifications make it easier to support.
The runaway train
But then there was the other side, the dark side.
There was that time where a script started spawning child processes that blocked up a critical process, or the time that the hopen did not hclose and was polling repeatedly, or the time when the hopen logic got called a few thousand too many times, or the time when the user knew kdb+ but not enough kdb+…..
OK so they are bugs,
- developers are mostly human which mean mistakes happen,
- testers and automated checks don’t always catch all these “features” inside the appropriate environment
- end users might do their own thing, with consequences
But the key thing for all of these was that each kdb+ process said NO, stop, you have exceeded – now like Bradley Cooper, they are limitless*
* Connections are constrained of course by the architecture, but then you can’t use a Bradley Cooper reference

So?
So my thoughts here are that this change in 4.1 is fantastic, it will result in the capability for handling increased capacity and potentially simplifies some monoliths. I can only imagine the number of clients and folks who have requested this feature for years.
And my thoughts are also – let us exercise caution here – think about Jimmy who has got to section 1.19 in Borrors book, read about hopen, saw “Now we’re ready to party” and decided to party on dude.
As such we need to consider whether we had monitoring in for open connections – whether its a count or details we should consider this so we can keep the train on the tracks. The way I see it, we have a few options here:
1. Start monitoring .z.W via metrics capture or through opening and closing handles
2. Leverage the OS to add constraints around the number of file descriptors (ulimit -n)
Let’s be honest this is probably something we should have had before, a part of understanding metrics in our systems but we always had that safety net.
My advice – TRUMP it
Think, Review, Upgrade, Monitor, Productionize
Share this: