Jonny Press
At Data Intellect we have been collaborating with AWS and KX, integrating our TorQ framework to work seamlessly with Amazon FinSpace with Managed kdb Insights. In this blog we will explain how we migrated TorQ, and give some pointers to anyone else who might be considering a kdb codebase or framework migration.
The Challenge
Capturing, persisting and analyzing real time data is a challenging problem. Daily data volumes can be fixed (such as a smart meter sending a reading on a pre-set schedule) or fluctuate (such as website traffic, or price quotes in foreign exchange markets). Data may be discarded, but given that future analytic use cases are usually unknown it is common to maintain data indefinitely at full granularity. Well built systems tend to attract additional users and business use cases.
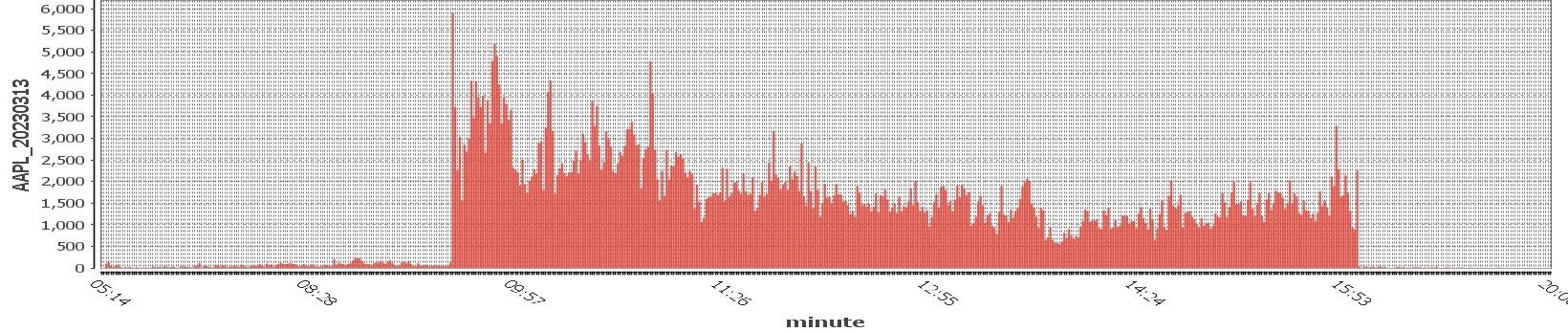
If we look at some specific financial market examples, an intra-day profile of AAPL quote volume is shown below – note the high data rates at market open.
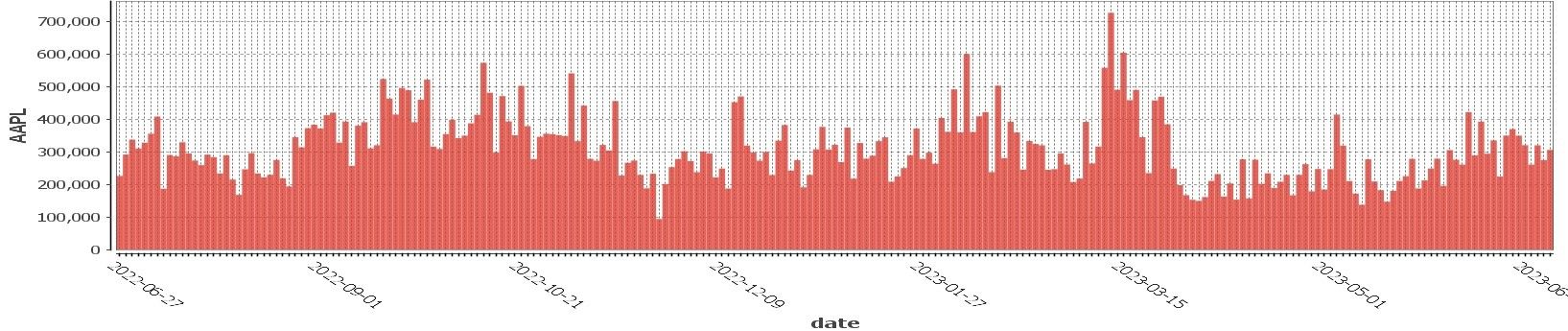
A daily view of AAPL quote volume is below. It can be seen that on most days, having sufficient capture capacity for 400k updates would suffice, but there are many days with higher volumes including a peak of 750k updates.
An ideal data capture system needs to be able to cope with:
- Fluctuating capture rates, including sudden spikes.
- Increasing data volumes over time.
- Persistence of historic data indefinitely.
- Increasing volume of user requests against longer and longer data histories.
The ideal solution will likely require flexibility and scalability at both the hardware and software level.
Enter Amazon FinSpace with Managed kdb Insights
AWS and KX launched Managed kdb Insights in June 2023. kdb Insights is the timeseries database and analytics engine from KX, used by leading organisations to capture, analyze and store huge volumes (think multi-Terabytes) of data in real-time. Managed kdb Insights provides a managed environment for deploying new or existing kdb applications on AWS infrastructure. The driver behind Managed kdb Insights is to ease the development and operational burden on kdb applications by making it easy to configure, manage and run at scale kdb workloads on AWS.
At Data Intellect we like the approach of lowering the development burden and to have a standardised approach to standard problems. That was one of the original drivers behind our kdb framework, TorQ, which is the backbone of many kdb data capture installations. Over the last number of months we have been collaborating with AWS and KX to ensure TorQ is fully interoperable with Managed kdb Insights. The target outcomes are to:
- Create a migration pathway to allow TorQ users to migrate easily to Managed kdb Insights.
- Give a leg up or head start to firms wishing to build from scratch or migrate existing applications to Managed kdb Insights.
What is TorQ?
TorQ is our open source kdb+ framework, released in 2015. TorQ provides a default data capture architecture and solves a number of common problems encountered in a kdb+ system build out.
A basic example TorQ data capture architecture running on two Amazon Elastic Compute Cloud (Amazon EC2) instances is outlined below. A lot of TorQ deployments would be similar to this, and the architecture should be familiar to anyone who has used a kdb+ tick style data capture system (if it’s not familiar and you would like to learn more, you can read up on KX or get in touch). TorQ consists of a number of separate data capture and access components and in this example requires both local storage and shared storage.
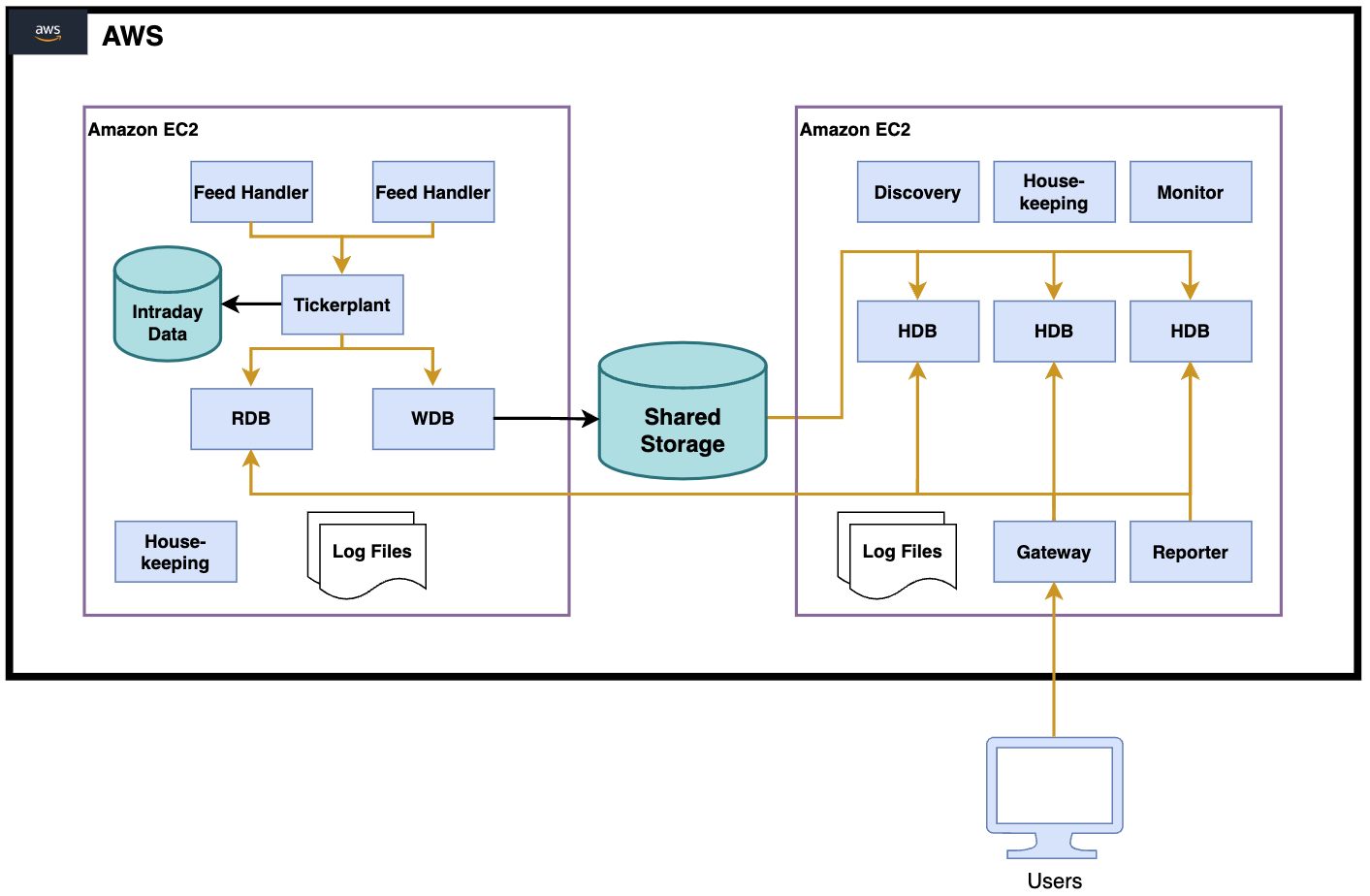 Describing the detailed function of each component is outside of the scope of this article, but in summary:
Describing the detailed function of each component is outside of the scope of this article, but in summary:
- Data is received and parsed by Feed Handlers.
- Feed Handlers push data to a Tickerplant which writes it to an on-disk log.
- The RDB (Realtime Database) and WDB (Writing Database) subscribe to the Tickerplant and receive data.
- The RDB creates an in-memory view of the most current (“today’s”) dataset.
- The WDB logs data to disk, and moves it to the Shared Storage at the period finish (end-of-day).
- The HDB (Historic Database) accesses historic data from disk and serves user queries.
- The Gateway provides a single point of access and a consolidated view across disparate processes.
- The Housekeeping, Discovery, Monitor and Reporter processes are ancillary TorQ processes.
How does Managed kdb Insights approach the challenge?
Managed kdb Insights approaches kdb+ from a lowest-common-denominator view point, and doesn’t try to mandate a specific way of doing things, with the exception of using managed storage for data.
Managed kdb Insights provides several types of cluster to deploy kdb+ applications. A cluster is defined by its capabilities – primarily the resources it has available to it (for example managed storage, or locally attached disk). Each cluster can contain one or more nodes which map to kdb processes. A cluster can be configured to scale up or scale down the number of available nodes based on load.
Managed storage is the Managed kdb Insights approach to long term data storage. Managed storage is updated by pushing changesets, which allows a version history of the database to be built. The changeset mechanism also allows different versions of the data to be made available to different nodes. Managed Storage is built on Amazon S3 and leverages the associated resilience and scalability. An Amazon FSx caching layer can be deployed in conjunction with managed storage to provide a query performance improvement.
At General Availability, Managed kdb Insights provides four types of cluster:

Managed kdb Insights simplifies integrating your kdb applications into AWS tooling by centralizing the capture of logs and performance metrics to Amazon CloudWatch, utilizing AWS Identity and Access Management (IAM) for access control to your databases and clusters, and aligns with the infrastructure-as-code paradigm using the AWS Command Line Interface (AWS CLI) or Terraform.
A key point with Managed kdb Insights is the automatic adherence to Information Security Policy best practice. In a non-managed environment these requirements will fall into the remit of the kdb application development teams- they require management and are a diversion from delivering business value. These include:
- Adherence to Identity and Access Management policies.
- Encryption of data both at rest and in transit.
- Secure connection strings with expiries.
- Timely upgrade of kdb+ versions.
- Hardware patch management.
- Network isolation.
TorQ on Managed kdb Insights MVP
A standard TorQ installation usually consists of two parts:
- The TorQ framework code. Configuration, library code and process templates required to stand up an application;
- The application code, which utilises the framework code to implement an application.
An example of (2) is the TorQ Finance Starter Pack (TorQ FSP) which is a Financial Services oriented data capture system which generates and stores mock market data. A common approach that several TorQ users have taken is to use this as the base for a production application, usually only modifying the schema and data feeds.
To migrate to Managed kdb Insights we needed to do two things:
- Make changes to the core TorQ framework to support Managed kdb Insights whilst maintaining backward compatibility for non-Managed kdb Insights installations.
- Create a Managed kdb Insights specific version of the TorQ FSP, known as the TorQ Amazon FinSpace Starter Pack.
The resulting MVP architecture is detailed below. It is in essence a stripped back version of the TorQ Finance Starter Pack which focusses on the RDB, HDB and Gateway query components. Some of the standard TorQ components, such as the Housekeeping process and the Reporter, are no longer required in Managed kdb Insights as the functionality they provide is already implemented in Managed kdb Insights or would be better implemented using already available AWS services such as AWS Lambda or AWS Glue.
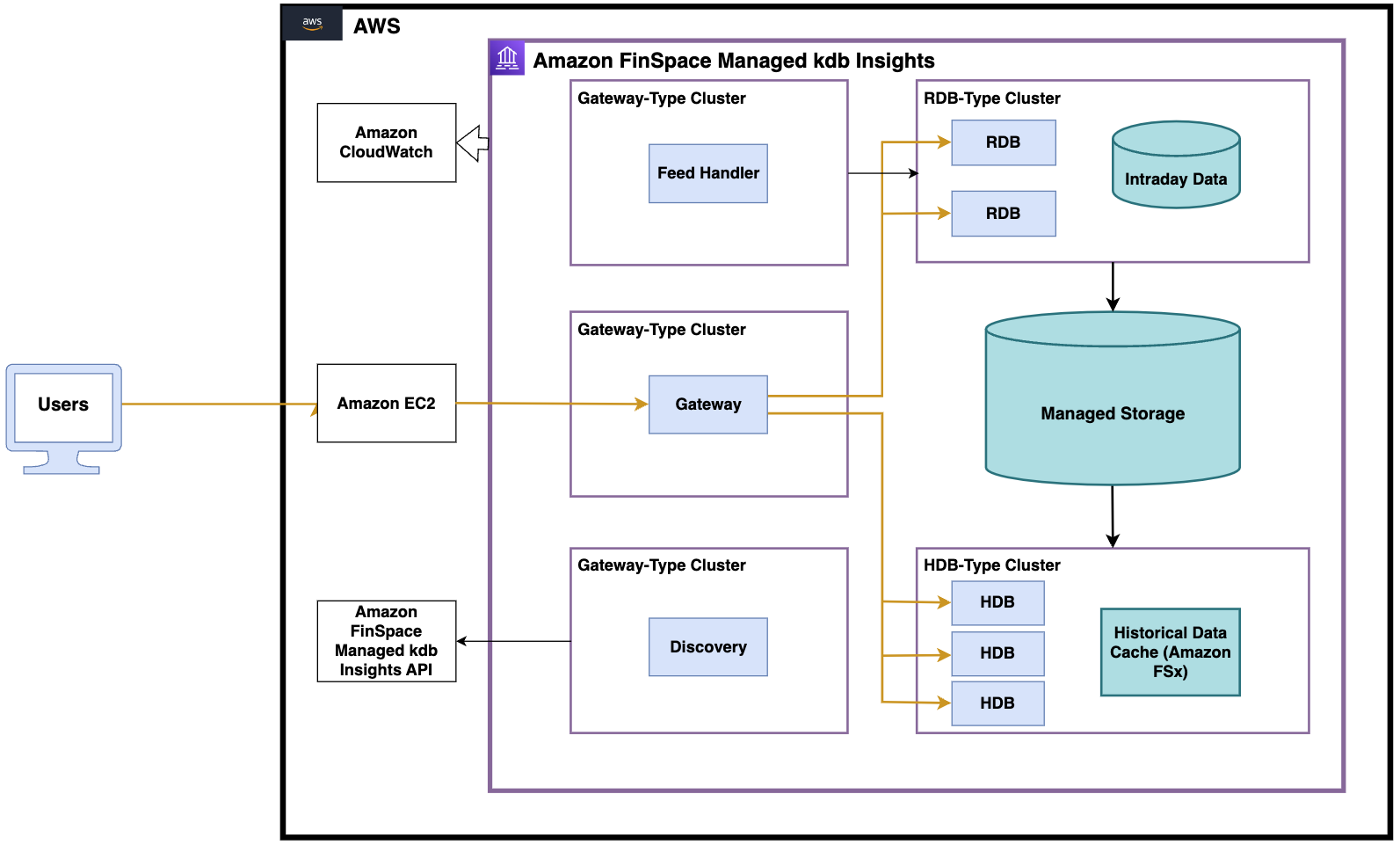
The changes required for Managed kdb Insights integration were:
- Integration with the Managed kdb Insights Discovery API. Within TorQ, a Discovery service allows processes to register their availability and capability, and to find other processes that they need to connect to. The Managed kdb Insights API allows discovery of both clusters and nodes within clusters. Rather than re-write the discovery layer, we felt the safest initial approach was to run a standard TorQ Discovery service but have clusters use the Managed kdb Insights Discovery API to find and connect to Discovery.
- Change in how message handlers are defined. Managed kdb Insights reserves the definition of message handlers to ensure that they can undertake specific housekeeping and security measures. The consequence is that any custom definition message handler definition is done inside the .awscust.z namespace rather than the standard .z namespace.
- Change in connection logic. Managed kdb Insights uses an anonymised connection string, which isn’t reliant on host and port information. The connection strings are more secure as they are validated against IAM credentials and have an associated expiration. Once the connection is established it behaves in the same way as a standard (encrypted) kdb IPC handle.
- Leverage Amazon CloudWatch for log files. TorQ uses three log files: standard out, standard error, and usage (queries). Managed kdb Insights automatically pushes all standard out and standard error messages to Amazon CloudWatch. Usage logs are redirected to standard out to also reside in CloudWatch, leading to a single time ordered view of all support data across all nodes.
- Fewer auxiliary processes. The TorQ Housekeeping process is no longer required as the log files don’t exist. The Monitoring process is expected to not be required, and we will be able to integrate metrics and monitoring information directly with Managed kdb Insights. The Reporter process will likely not be required as the same functionality can be implemented with standard AWS tooling.
Creating Best Practices and Leveraging AWS
Managed kdb Insights provides a managed, secure environment for deploying kdb+ code. It removes the need for a kdb application development team to take on infrastructure-oriented tasks, and aligns by default with infosec best practice. It also opens up the world of AWS services to kdb+ applications. Specifically:
- Simple AWS API to launch fully configured, secure, and scalable AWS infrastructure for kdb, making it easy to get started with kdb on AWS.
- Launch new kdb infrastructure in minutes, and shut down when not needed– saving $ and allowing us to provide kdb for teams on demand.
- Ability to scale hardware capacity- move to bigger cluster sizes as data volume or user load increases.
- Eliminates all hardware and software maintenance, such as OS patching, security patching, and kdb patching.
- Integration with AWS Identity and Access Management (IAM) for user access control to kdb clusters and databases.
- Automatic encryption of data in transit and at rest using a customer provided AWS KMS key.
- Autoscaling of HDB capacity through a set of simple configuration parameters, negating the need to wrap an orchestration tool around it.
- HDBs are easily configured to run across multiple Availability Zone for resiliency.
- The use of S3 for HDB databases storage reduces storage cost and provides high availability and usage scalability across multiple services.
- The configurable, rolling Amazon FSx caching that sits in front of the Amazon S3 storage provides a performance boost.
- The automatic propagation of logging data and kdb related metrics to Amazon CloudWatch provides excellent visibility to support teams.
- The ability to deploy the environment easily from Terraform using the infrastructure-as-code paradigm leads to easy replication of environments.
- Natural integration and utilisation of other AWS services.
Additional Considerations: Automatic Memory Scaling
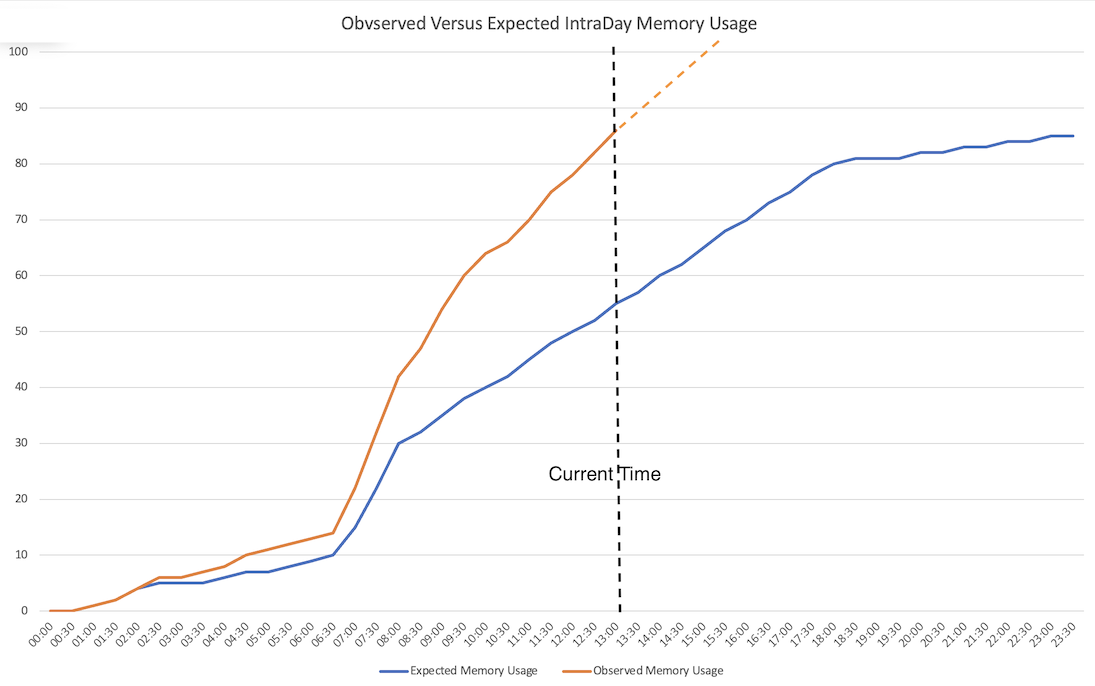
The nodes within a cluster require the memory size to be pre-defined. There are a number of components in the architecture with a memory footprint which is potentially large and unknown in advance. Cloud deployments such as Managed kdb Insights remove the need to estimate how big the problem might get over the next N years when procuring hardware, instead requiring an estimate for the coming day or week.
A memory scaling approach could be built by the developer within Managed kdb Insights. The metrics published to CloudWatch can be analysed and compared to the historic profile, and if thresholds are predicted to be breached a larger replacement cluster can be brought up in the background and workloads migrated without downtime. However, it would be better if this was done automatically and the Managed kdb Insights cluster size grew with application demands.
Looking to the Future
The DI Team have enjoyed getting to grips with Managed kdb Insights and working with the AWS team. The AWS team have educated us on their product and approach, and our feature requests and modified approaches have been received well.
Throughout 2024 we plan to incorporate Managed kdb Insights roadmap items as they become General Availability. We are also going to experiment with the TorQ architecture to investigate how we fully utilize the flexibility that Managed kdb Insights provides. In the pipeline we have new approach for managing intraday data which will be specific to Managed kdb Insights.
Getting started with Managed kdb Insights using TorQ
The easiest way to get started is to install TorQ and download the TorQ Amazon FinSpace Starter Pack. Full startup instructions can be found in the TorQ Amazon FinSpace Starter Pack documentation. The full set of changes required to make TorQ with Managed kdb Insights can be found on this Pull Request.
If you have any issues or questions please get in touch. We also have a Google Group for questions and discussions.
Share this:
















