Read time:
6 minutes
Cormac O'Neill
The Abstract
In many data and analytics projects there is one problem that seems consistently challenging: capturing, processing, and storing large tables. Generally speaking, the hardware used for these projects can manage the bandwidth and size of most of the tables in the project database, however this is not guaranteed. Be it a symptom of reluctant budget managers or voracious data consumers, in some cases the machines that host the data capture systems for these projects are limited in what they can process. These limitations can lead to a myriad of issues as bottlenecks are introduced that can back up the entire data capture pipeline, they can also come in a variety of forms: compute resources, storage space, disk I/O speed, etc. This can affect data quality as well as availability owing to both inaccuracies in recovery measures and delays between capture and write-down. In a field where every datum counts, every effort must be taken to avoid any loss of data reliability, even when the resources available to address the root cause are restrictive. Sometimes though, these large tables are not required in real time as they might be used for T+1 research only, as such we have much more flexibility as to how we can persist them.
The Problem
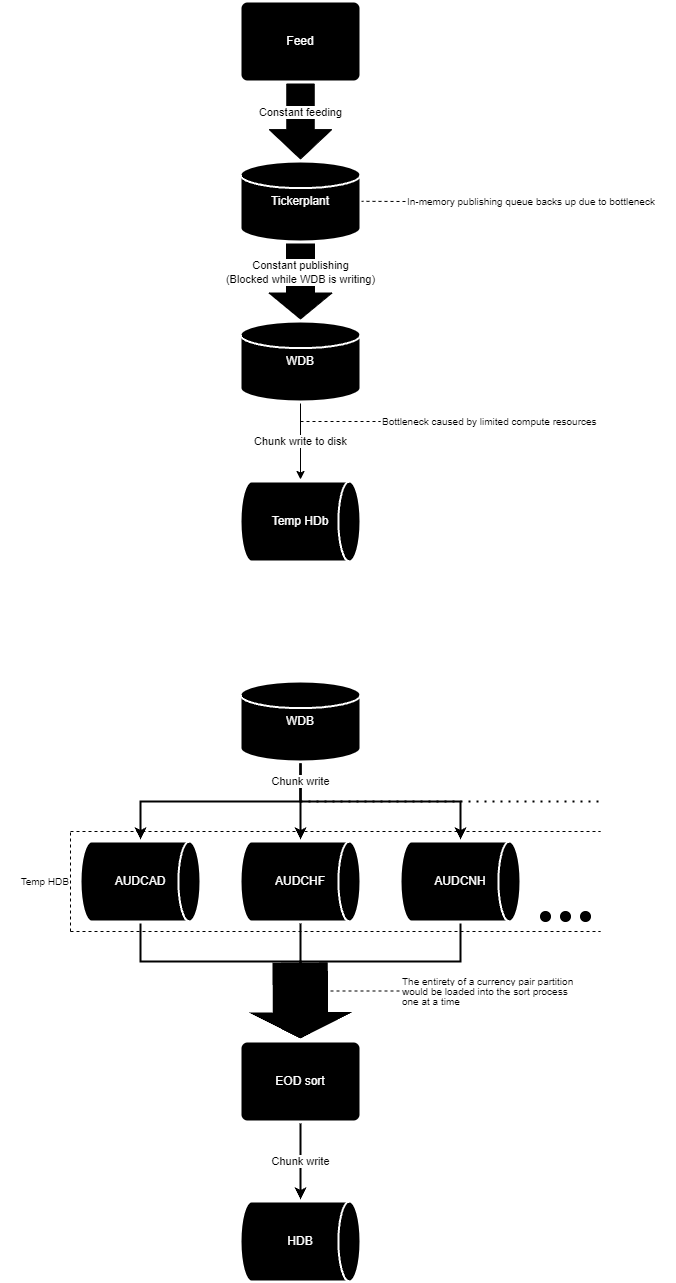
To move away from the abstract, I have recently worked on implementing a solution like the one described above, with similar restrictions and bottlenecks. The main complication was that there wasn’t enough compute resources for the amount of data we were taking in, which led to a bottleneck in our WDB write down which backed up the Tickerplant update queues, increasing Tickerplant memory usage as they were unable to flush data to the WDBs fast enough. This in turn meant that there was a significant discrepancy between when the incoming data was received by the Tickerplant and when it was written down to disk. The sheer volume of incoming data exacerbated this issue to such a degree that the Tickerplants were regularly exceeding the maximum available RAM on the server, crashing and disrupting the entire data capture pipeline.
This system utilised Kafka with some common recovery measures that allowed messages to be replayed to the capture process on post-failure-startup, with offset values being used to determine where in the recovery queue to begin replaying messages from. However, if the discrepancy between capture and write down exceeded the duration that the recovery queue retained, then any data the Tickerplant had stored in memory from before that duration would be permanently lost. This bottleneck led to regular data loss and even in cases where no data was lost, there was regularly duplicate data being fed to the Tickerplant. This was because the implemented logic for saving the offset values was sub-par, leading to inaccurate values being used for recovery.
The intake volumes in this project being as massive as they were also led to issues with the EOD rollover. These tables would be initially saved to folders divided by currency pair, then sorted into the HDB at EOD, a process which, in our case, often took up to 12 hours to fully complete owing to the sheer size of the tables. This meant that data for these tables were not available for querying until the afternoon of the day after it was captured. This EOD sort would load into memory and write to disk the entirety of each currency pair partition one at a time. However, the volume of EURUSD data captured during a day would often exceed the maximum available memory on the host server, crashing and, depending on where exactly the sort process crashed, could irrecoverably corrupt data.
The options for addressing all of these issues were limited, the go-to solution of adding more Tickerplants was not possible as we could not make upstream changes to how the data arrived, neither could we add more WDBs as we were already maxing out CPU utilisation with the current architecture. A more drastic solution was required.
The Solution
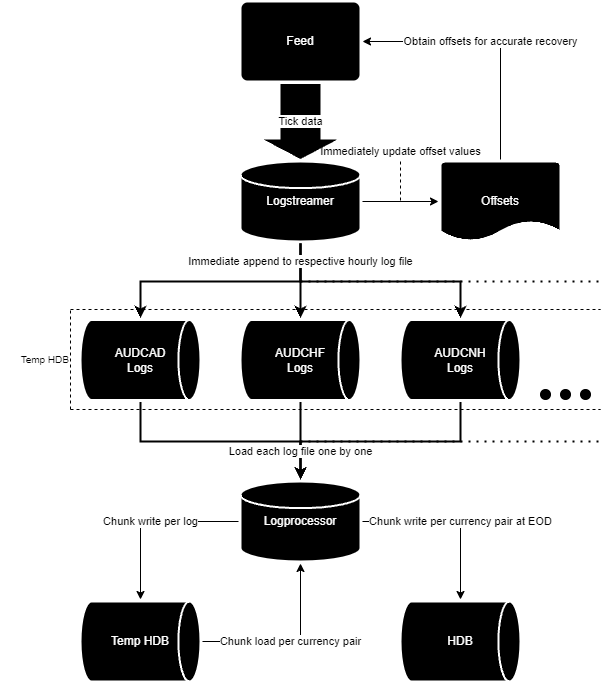
Without the possibility of altering the upstream configuration or increasing compute capacity, a creative workaround had to be developed, which ended up being a complete rework of how these tables were captured. The result was an extremely rigid, but lean, efficient, and reliable data capture pipeline that significantly improves the volume capacity we can handle for these tables. The plan for this pipeline was to create two new processes: the Logstreamer, and the Logprocessor
The Logstreamer is the replacement for the standard TorQ Tickerplant. Being solely responsible for data intake, it is purpose built to expect and process update messages for exclusively this project’s problem tables and immediately write them to disk without alteration to a series of log files divided by currency pair, and then further divided by a configurable time period (1 hour by default). It maintains a record of the latest offset value so the recovery queue will still work with this new process in the event of a failure. Every period rollover, the Logstreamer sends a message to the Logprocessor containing a list of the log files from the hour that just finished and whether any EOD operations are required, it then stops writing to the log files for that hour and begins writing to a new set of log files for the coming hour.
The Logprocessor kicks into action when it receives the end-of-period message from the Logstreamer, prompting it to begin parsing the log files that the Logstreamer sent over. It reads in the messages stored within the log files and writes them to disk in batches, still divided by currency pair. There also exists logic in this process to check for any log files that may have been missed owing to a failure of either the Logstreamer or itself. This check is carried out on start-up and every period rollover thereafter so recovery is seamless. At the end of the day, the Logprocessor begins sorting the currency-pair-divided tables with an incorporated version of the optimised EOD sort mentioned at the end of the previous section. This new system is ~85% faster (taking about 90 minutes to sort a day’s worth of data that would have historically taken up to 12 hours), more efficient (taking max. 330GiB of RAM), and more accessible (Intra-day data is available as soon as the period it was captured in has rolled over. EOD sorts finish up at 01:30 the day after capture) than the previous pipeline.
The Result
This streamlining that we have carried out has led to a system that is:
1. More stable owing to robust automatic recovery measures minimising the need for manual intervention and risk of human error, as well as the optimisation of memory usage making failures far less frequent.
2. More efficient, using a maximum of 350GiB of RAM where the previous system regularly exceeded the total memory capacity of the server, leading to frequent crashes.
3. Faster, taking around an hour or two to sort a day’s worth of data where the previous system often took up to 12 hours, this also extends to intra-day accessibility; the previous system often lagged behind as far as 14 hours in some cases, this new pipeline lags behind a little at peak times but catches up with itself long before EOD.
This new architecture is more lean and reliable than before, as there is less data stored in memory at any given time, the data capture and write down processes are decoupled from each other, removing any dependencies between the two, and the complex recovery actions that were once the responsibility of humans are now automatic, offloaded onto the logprocessor, reducing the risk of human error. What we have essentially done here is isolated the logging and writedown functionality from a standard TorQ setup and made it the primary data capture pipeline, eliminating any intermediary operations that may bottleneck the flow of data, leaving only that which is strictly necessary.
Share this:
















