Matt Doherty
Introduction
Hype cycles come and hype cycles go. Big data, 3D printing, IoT… These usually come in the form of a core innovation, immediately surrounded by layers of sales and grifters, and often underdelivering on their initial promise. We live in the age of the generative AI hype cycle, but – and I might eat my words later on this – this one feels a bit different.
In general my opinion on these tools at the moment is that the limit is our creativity as users, as much as the tool itself. Most “engineering” advances come in the form of tools that are better and better at the specific tasks we design them for, but using LLMs (large language models) feels much more like an act of discovery. They are not designed specifically to write poems, or pass the bar exam, or act as a roleplaying DM. They just seem able to do it. And in a very real sense no one – not even the smartest researchers who built these tools – knows exactly why. Perhaps the largest reason I’m personally sold on LLMs is that the use-case as a programming assistant has already been incredibly useful to me. It’s so insanely good at this out of the gate, it seems unlikely there won’t be other things it’s amazing at.
Using the SQL Agent
A specific problem I had recently involved querying data from the internal sys tables in SQL Server to answer a very specific question, something I’m not super familiar with. ChatGPT 4 produced a perfect 30 line SQL statement joining 3 tables, using a special internal function and even renaming columns for me to make the meanings more obvious. I’m far from the first person to discover that this is something LLMs can do – OpenAI themselves have examples dedicated to it – but it’s powerful enough that it’s worth spending time on.
Natural language to SQL is not a new thing. Older models have done it with some success, but modern LLMs blow it wide open. Not only are they as good or better than old fine-tuned models (depending on who you ask) but they “know” a lot of other stuff that can be really useful (more on this below).
And on top of the use case of natural language to SQL, I’m going to add the idea of data aware, “agentic” language models. This is fancy language for allowing a language model to interact with it’s environment. So rather than the model providing SQL for us to run, the model can run SQL itself and use the results to answer user questions.
As I said this is not a new thing, so what am I doing here that’s different? Two key things that should hopefully make this different enough to be interesting:
- The database is kdb+ rather than a more standard SQL database, so this might be first instance of LLMs interacting directly with kdb+ via q-sql rather than a more restricted API (see below for exactly how)
- We’re going to use a database of typical finance data (trades and quotes) so we’ll show some examples very specific to this use
SQL Agent Setup
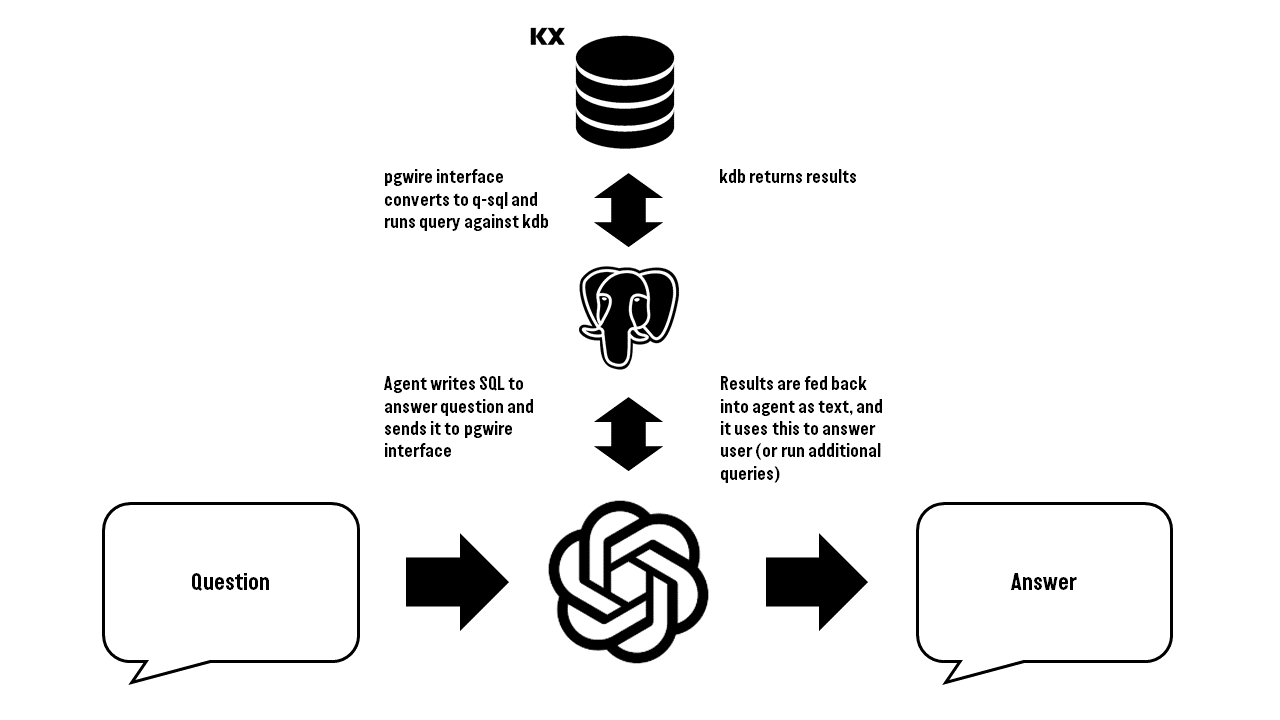
This is how our basic setup looks, with three main pieces:
- The agent itself orchestrated with a set of simple python scripts. I’m using a technique called “few-shot prompting“, which basically means telling the agent upfront what you want it to do, giving it some information about the database and how to query it, and giving it some sample questions and answers. This area is full wild west and no one really has any idea why stuff works or doesn’t, they just try and see (see my earlier comment on discovery rather than design). Our specific prompts are in plain text here if anyone is interested
- pgwire interface to kdb+ to handle conversion of SQL to q-sql queries. Even though our previous post showed LLMs can generate q-sql, their knowledge of standard SQL is much better so we’re combining that with this specialized conversion layer. I believe this should be more robust and powerful than going directly to q-sql
- A kdb+ database with two days of NYSE TAQ data. This has standard trade and quote tables, and has x rows, and y size on disk
For those who are interested in more details you should be able to reproduce most of our setup with the linked repo. Setting the details aside, the key thing here is with a language model acting as an agent you can ask it a question in natural language and it can access our financial dataset (as well as it’s own internal “knowledge”) to help it answer the question. We’re not using LangChain, but it’s worth mentioning as it’s the “standard” tool in this space and can do a lot more, connecting agents to all manner of external sources they can interact with. All examples are using gpt-3.5-turbo (we also tested gpt-4 and comment briefly at the end).
Ok, time for some real examples...
Smarter people than me have previously done more rigorous benchmarking to try pin X% accuracy to these models in various setups. That will not be the focus here. Instead we’re more interested in interesting things specific to our use case, and pushing the limits a little and trying to be creative. As I said earlier I think this is the best way to approach LLMs, is as an act of discovery as much as design.
So let’s head straight into our examples. For every example I’m copying direct output from our console prompt, showing:
- The question exactly as I typed it
- Any SQL queries the agent executes against the backend (we don’t have to show this but it’s very interesting to know. The answer it gets back from the database is not shown)
- And finally, the answer to our question
For each I’ll include some comments of my own, but hopefully they all speak for themselves.
1
Question: Can you find me the total dollar value traded of Apple stock on 2019-10-07? Give the answer as a percentage of the total market cap, which is 3 trillion dollars
Generated SQL:
Executing Query:SELECT SUM(Trade_Volume * Trade_Price) FROM trade WHERE Symbol = 'AAPL' AND date(Time) = '2019-10-07'
Executing Query:SELECT SUM(Trade_Volume * Trade_Price) FROM trade WHERE Symbol = 'AAPL' AND Time::date = '2019-10-07'
Answer: The total dollar value traded for Apple stock on 2019-10-07 was $7,202,587,000. This represents approximately 0.240% of the total market cap of $3 trillion
So the SQL it generates is great, and although the question is fairly simple already there are several things worth comment here:
- It knows to search for AAPL (the stock ticker) not Apple. There is no reference data store in our database, the agent simply knows this mapping and knows to use it.
- I didn’t specifically tell it what dollar volume is, again it already knows or figures it out.
- The first query fails, so it sees the error message and tweaks it and tries again (!)
- It does the ratio of market cap maths itself, this is not included in the SQL query (!)
- And most importantly the answer is right
2
Question: Can you find me the closing auction prices on 2019-10-08 for a range of meme stocks?
Generated SQL:
Executing Query:SELECT Symbol, Trade_Price FROM trade WHERE EXTRACT(YEAR FROM Time) = 2019 AND EXTRACT(MONTH FROM Time) = 10 AND EXTRACT(DAY FROM Time) = 8 AND Symbol IN ('GME', 'AMC', 'BB', 'KOSS') AND Sale_Condition LIKE '%M%'
Answer: Here are the closing auction prices on 2019-10-08 for a range of meme stocks:
AMC: $9.83
BB: $4.88, $4.89
GME: $5.22
KOSS: $2.04, $2.00
- So here it knows with no further explanation what a meme stock is, and knows a range of tickers to search for
- It is able to handle building a LIKE conditional to find closing auctions (the initializing prompt tells it about some condition codes, it knowing to use M would be really insane)
- It uses a different date filter this time? Weird
- Again most importantly, the answer is right
3
Question: Can you query the total dollar volume of a range of meme stocks, and make me an ASCII bar chart displaying them?
Generated SQL:
Executing Query:SELECT Symbol, SUM(Trade_Volume * Trade_Price) AS Dollar_Volume FROM trade WHERE Symbol IN ('GME', 'AMC', 'BB') GROUP BY Symbol
Answer: Here is the ASCII bar chart representing the total dollar volume for the meme stocks (GME, AMC, BB):
AMC: $35,372,820
BB : $79,412,790
GME: $45,181,640
[##### ] (AMC)
[############# ] (BB)
[######### ] (GME)
This is hardly going to show up near the top of \r\dataisbeautiful anytime soon, but how insane is it that it just does it!
4
Question: 2019年10月8日百度股票总交易量是多少
Generated SQL:
Executing Query:SELECT SUM(Trade_Volume) FROM trade WHERE Symbol = '百度' AND Time::date = '2019-10-08'
Executing Query:SELECT SUM(Trade_Volume) FROM trade WHERE Symbol = 'BIDU' AND Time::date = '2019-10-08'
Answer: On October 8, 2019, the total trading volume for Baidu (BIDU) was 4,517,812 shares.
So as you might guess by the answer this is asking for Baidu volume, and after one false start the agent gets it exactly right. No issues with non standard characters at all. In other examples not shown here I’ve also seen it respond in Chinese. And interestingly when doing something similar in German it also reformatted the date in the answer from YYYY-MM-DD to DD-MM-YYYY because that’s what’s more common in Germany (wat).
5
Question: Can you look up the closing auction price for american airlines on 2019-10-07, and tell me the price in the form of a short poem?
Generated SQL:
Executing Query:SELECT Trade_Price FROM trade WHERE Symbol = 'AAL' AND Time >= '2019-10-07 15:59:59' AND Time <= '2019-10-07 16:00:01' AND Sale_Condition LIKE '%M%'
Answer: In the closing auction, American Airlines took flight, with a price that shimmered and shone so bright. At 25.815, it made its mark, a final trade in the evening’s dark. As the curtains closed on this trading day, American Airlines had its say.
Closing Thoughts
So hopefully this has at least served as yet another demonstration of the slightly magical abilities of modern LLMs. As ever I’m pretty blown away. However, in the name of balance it’s important to take the other side here too.
It still makes silly mistakes fairly often. For example I asked for the return on some stocks and it simply took the difference between the max and min price. I tested this same question with the larger gpt-4 model and it did produce a correct answer by querying twice for open and close prices, but it confidently failed (or hallucinated) for trickier questions like asking for the maximum intraday drawdown.
In one of the earlier cited papers using the spider SQL benchmark, LLMs do very well, but very well in this context is 90-95% correct. This is no where near good enough for most real use-cases. If this was deployed as-is as a query tool, the kind of user most likely to use it is almost by definition least well equipped to tell when it’s made a mistake. The short context window is also something of an issue (there’s a limit to how much you can tell the model in the initializing prompt). Here’s an excellent blog talking about some of the challenges of going from these magical abilities to a real product. And another quote particularly relevant to this use case:
Writing the actual SQL query is not the hard part for us. The hardest part is exhaustively expressing our intention in any language at all, followed closely by its apprentice – the incomplete requirements monster.
The model won’t necessarily tell you if your question is bad, or unclear, it might just make assumptions and answer. LLMs tend to be somewhat overconfident, at least in my experience. How to test any application taking advantage of LLMs is also something of an open question, when the range of possible inputs is all human language.
Having said all this, I don’t think this should dull our enthusiasm for this tool. Smart people are working on all these issues, using embeddings and all sorts of other clever tricks. However, for me the amazing thing about LLMs is that they’re incredibly general, and not just geared towards any one use case. We’re not building it for one thing, trying it, then saying oh well and moving on. The limit here is as much our creativity in what to use these tools for, as the tool itself. I still think we’re going to see some fairly amazing things in the next few years.
Share this: