Project Redshift
Megan Morelli
The Challenge
In the sense of Annie Get Your Gun’s adage “Anything you can do I can do better”, the world of cloud computing is driven by leading tech companies constantly one-upping each other.
This can become extremely overwhelming for users. Is Amazon’s AWS best suited, with its free tier allowing you to play around with the console and its services? Or maybe it’s Google’s GCP, with its straightforward permissioning. What about Microsoft’s Azure, with its easy-to-use user interface and services? At Data Intellect, we want to do the hard work for you. Investigating these cloud providers and their services and building a bridge between a kdb+ process and your data, stored in your chosen cloud warehouse.
Project Redshift: Just as cool as it sounds
Project Redshift (RS) was set up to investigate Amazon’s Redshift: an end-to-end petabyte scale and fully managed data warehousing service hosted on Amazon Web Services (AWS). Much like kdb+, Redshift runs on columnar SQL, and also uses Machine Learning to optimize data storage for faster queries. It’s comparable in functionality to Google’s Big Query, Snowflake, and Azure Synapse.
The outline for Project Redshift was to create a method of querying data that lives in Amazon RedShift from q, as well as to be able to write data into Amazon RedShift taken from a kdb+ process. This would allow users of the project to maintain a disk-hot/cloud-cold database model that captures the best of both worlds in terms of highest performance for hot data, and reduced costs for colder data. The project should result in a standalone model, working as an extension to TorQ, or as an easily configurable extension to users’ pre-defined kdb+ tick setups.
Utilising the 2-month Free Trial of Redshift Serverless, the project evolved to optimise development in this short time frame, with the project aims adjusting slightly to cater to this. By the end of the free trial, we had built both a standalone version and a TorQ-integrated version of the RS querying platform. In the TorQ version, users can query the gateway, and using the Data Access API, their query will be routed appropriately, either to the RDB, HDB, or Redshift process. Write ups to Redshift are performed by a WDB; the data is uploaded automatically from kdb+ to the Simple Storage Service (S3) bucket, and automatically copied into a pre-existing empty table in RS, ready for users to query it as needed. This can be likened to loading a table into memory to perform operations on it.
Our Architecture
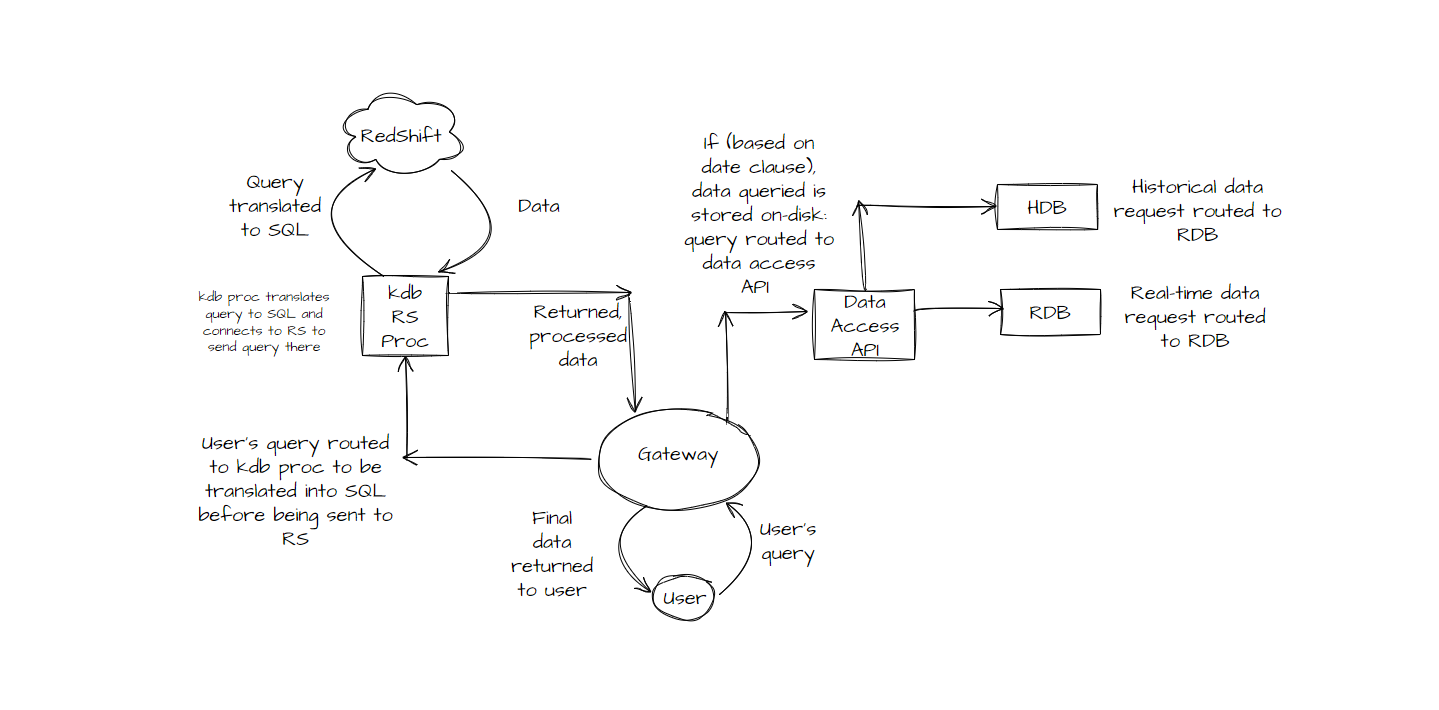
Our stylish diagram will give you a sense of how the project’s RS process will fit into things architecturally:
Taking a closer look here:
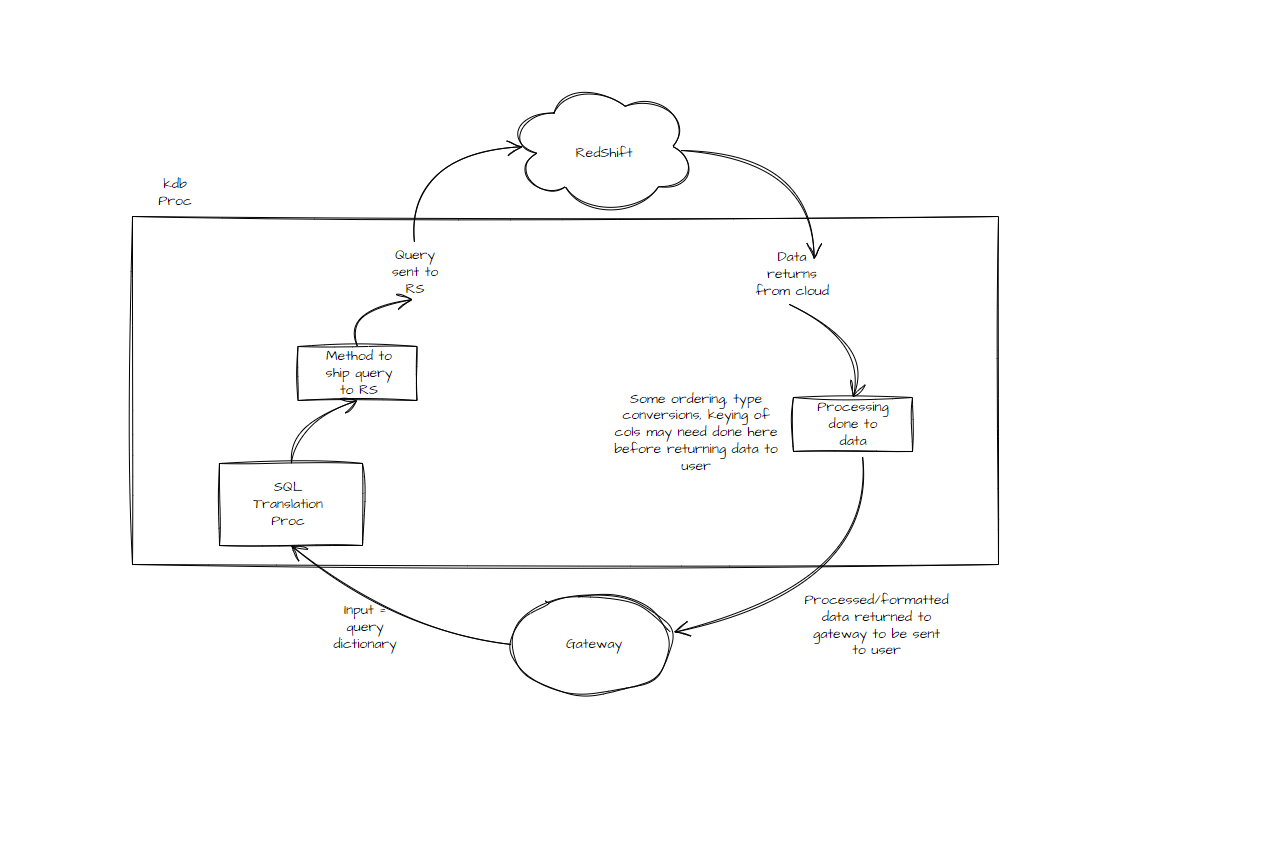
We see a more in depth view of the overarching architecture in the second diagram; further explaining the features of the designed process. Some of the important criteria we imposed in the architecture planning were:
- q inputs need to be translated to RS SQL – the translation process needs to cover a very wide range of differences between the two.
- A connection needs to be opened between RS and a kdb+ process – this could be something like an ODBC connection, a python connection, etc.
- Queries must be able to be sent from the kdb+ process to the RS cluster, and query the data there.
- Post-processing must be carried out on the kdb+ side of things before returning the requested data back to the gateway, and thus the user.
When incorporated into a tick stack, the user’s query will be sent to the gateway. When routed towards a RS process, a translation process will trigger, converting the user’s input dictionary into a SQL query. This will be routed to the RS process, which will send the query to RS. The requested data will be retrieved, conversions and post-processing carried out, and the resulting data will be returned to the gateway. The gateway will return these results to the user.
How It All Works ...
We connect our kdb+ process to our Redshift cluster through a python connector package. The credentials of the cluster are stored in environment variables, and the connection opened via a python function.
p)conn = redshift_connector.connect(host='aquaq-redshift-test-cluster.cvqbxeqzemr5.eu-west-1.redshift.amazonaws.com',
database='dev', user=os.environ['redshift_user'], password=os.environ['redshift_pass']);
p)cursor = conn.cursor();So, the connection has been set up between your kdb process and your RS cluster. S3 acts as a staging area for your data in the Amazon cloud. Your data is uploaded to an S3 bucket and can then be copied into Redshift tables from here. Data will be loaded into your cluster from your storage service, allowing you to run analytical workloads.
Translating Queries
Integration of the “transql” repository, kindly provided by Data Intellect’s BigQuery team, provides the ability to generate raw SQL statements from a kdb+ dictionary. Though similar at a high level, QSQL and RS SQL vary slightly in the details. As a result, though users may be well versed in SQL, a translation was required to convert the user’s input dictionary into a SQL which RS would understand. The translator works alongside multiple Cloud Data Warehouses, addressing differences, and altering the input dictionary as required. An example of just the translation function can be seen here, taking the input dictionary provided by the user, and converting it into SQL which RS will understand.
q).transql.getsqlquery `tablename`timecolumn`starttime`endtime`columns!(`date_upd_1;`date;2022.01.01;2022.01.01;`sym`amount)
"SELECT sym,amount FROM dev.aquaq_test_schema.date_upd_1 WHERE date = '2022-01-01'"An example of where the SQL can vary for different cloud providers can be demonstrated with Google’s BigQuery (BQ) and RS. BQ requires the table name to be surrounded by backticks, whereas RS doesn’t, and will fail if the backticks are included. The way to tackle this, but keep the SQL translator applicable to multiple providers, is to supply the kdb_sql_translator code with the name of your cloud provider. It adjusts the format of the query to accommodate for the differences we noted.
Standalone Querying
Redshift can also be queried through kdb+ without having to be incorporated within a stack. The setup is largely similar to the tick setup, but the process is started by calling the initialisation script directly. The interface provides detailed checking of all inputs so that errors are returned both quickly and insightfully. It’s also user-friendly for users both experienced and inexperienced in SQL querying. Queries can be generated from a kdb+ input dictionary or from straight SQL input. RS and kdb+ also vary slightly in their datatypes, so naturally, the return of the data from Redshift sees type conversion into kdb+ data types. And finally, before data is returned to the user, kdb+ post-processing options are applied. Users have both SQL and kdb+ at their disposal for querying in this sense.
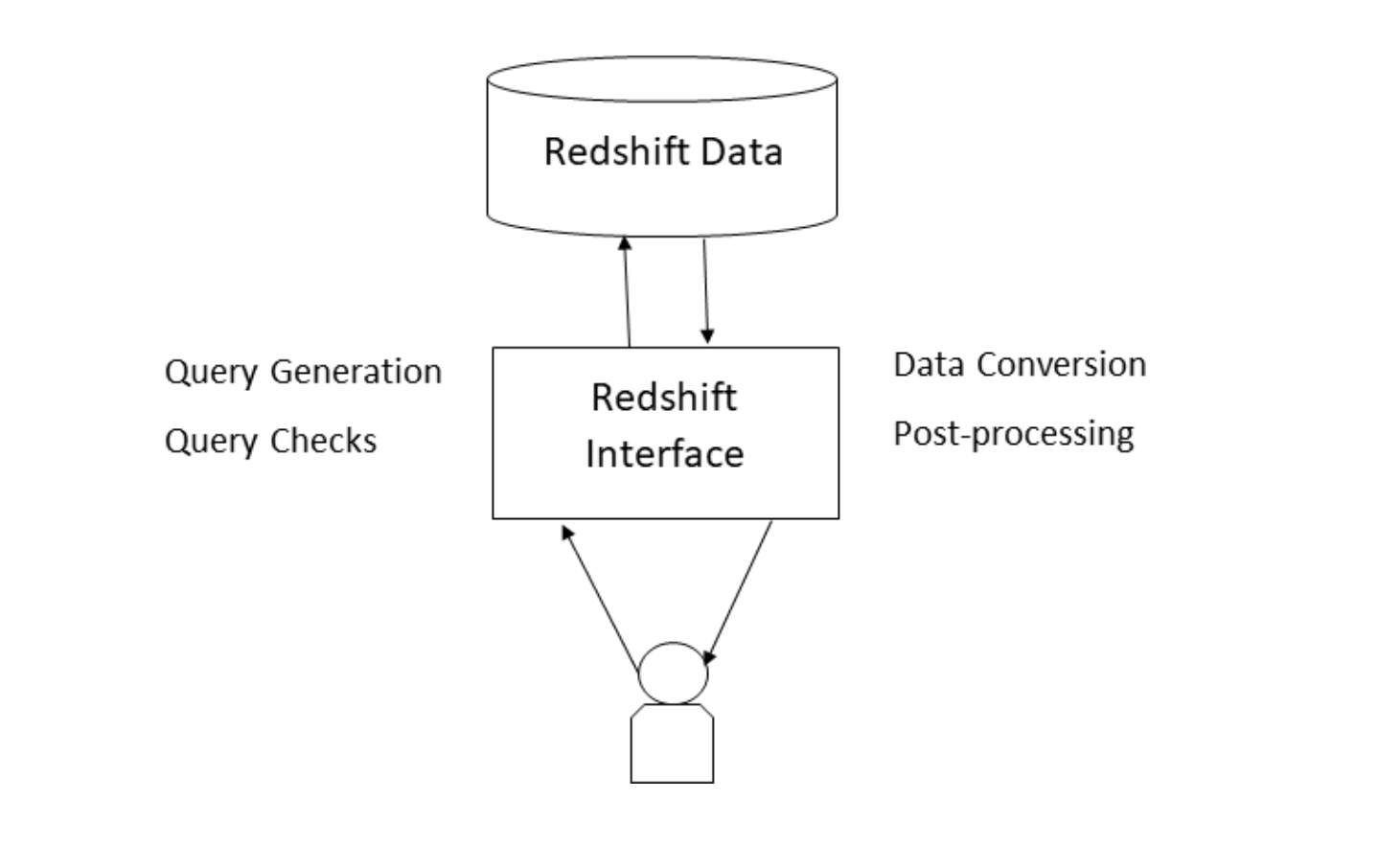
Querying from Your Stack
When incorporated into the user’s tick stack, and with the TorQ Data Access API enabled, users can query the gateway, and their queries will be routed appropriately. The function which will be called will be .dataaccess.getdata, and the user will supply an input dictionary which will form their SQL query. Users can specify post-processing and aggregations to be performed, and can query across multiple processes, such as an HDB and the RS process. Their queries will be routed based on the date provided in the input dictionary.
g".dataaccess.getdata `tablename`timecolumn`starttime`endtime!(`date_upd_1;`date;2022.01.01;2022.01.02)"WDB
A built-in WDB enables data to be pushed from the user’s tick system into S3 storage, for querying via Redshift. The write-down occurs via an intermediary file, which in this case is a Parquet file. Once data is translated to appropriate datatypes and written to a Parquet file, it is then pushed to an S3 bucket before being copied over to Redshift. Currently, the WDB is set to push intraday every N records; this is configurable, and a bit of an experiment. We plan that in the future we would configure things for the HDB to push to the RS-based WDB, so that users can store their historical data in RS/S3.
How is Redshift's performance?
Amazon Redshift achieves extremely fast querying by employing certain performance features, such as parallel processing, columnar data storage, and result caching. Here’s some stats from basic queries:
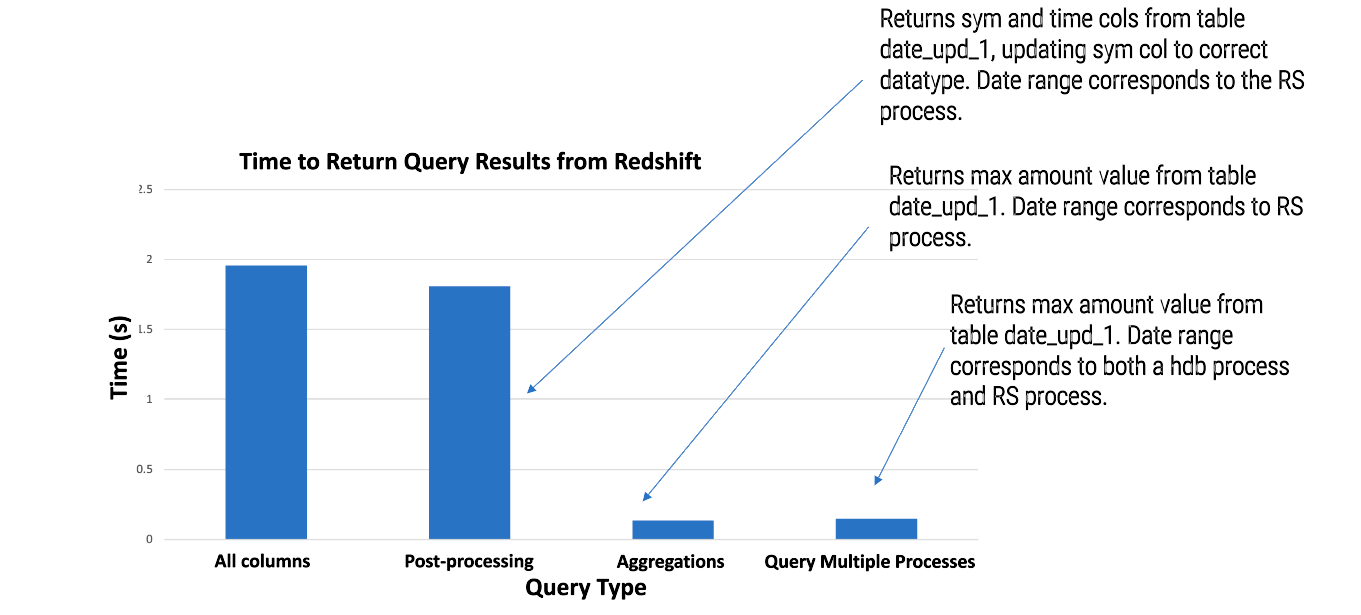
The same dataset was used for each query. There are a total of 40,000 records within said table. The entire dataset is extracted from Amazon’s eu-west datacentre, located in Dublin, Ireland, and returned to the user (querying from Belfast, N.Ireland) in under two seconds; a fair performance considering the datacentre location and size of dataset.
A query of just the sym and time columns with post-processing takes just a little less time than extracting the full dataset with no post-processing. Ideally, the data returned from Redshift wouldn’t need to be treated, but there are a number of datatypes that don’t carry directly over from kdb+ to RS equivalents.
You can see it is very quick when it comes to aggregating data and returning the result, taking around 0.2 seconds to do so. It did take slightly longer when querying across the RS and HDB processes, but this is expected as result sets from both must be joined/reaggregated before being returned to the user.
To summarise ...
Where does the project stand?
- Set up RS cluster and S3 bucket.
- Set up connections between a kdb+ process/TorQ stack and a RS cluster.
- Users are able to query data from S3 bucket copied into RS tables, from a kdb+ process.
- A RS-based WDB built, with auto-copying into RS tables.
- Users can query multiple processes, joining the data returned from the RS process and the additional process.
- Robust documentation, so that new members can on-board, and the system is user-friendly.
How could we build on this?
Since finishing the framework and stepping back to look at the project as a whole, we’ve identified some areas where we could do further building, improving the functionality of things further. Currently, the WDB in RS has the ability to push real-time data fed into the tickerplant to Redshift once a maximum number of rows is hit. We should also incorporate the ability to push data from a HDB into Redshift also. We would reference Data Intellect’s Big Query team’s work, as the functionality has been developed there and could provide some insight to streamline the process.
We would implement an automated clear out of the WDB data in our amazon S3 bucket: a function that is either called after each save down, or at end of day that will clear the S3 bucket of parquet files. This could be tailored depending on the decided functionality of the S3/RS data, whether it’s historical data, or a WDB doing intraday write-ups.
Currently if the table does not exist in Redshift or if there are other errors in the process of moving the data, there are no writes to the logs of the process. We would implement more frequent and insightful logging to both improve the user experience and help in cases of debugging for developers.
Conclusion
With the conclusion of the 2-month free trial, the project has not only met the initial aims, but has laid the groundwork for future development, with robust documentation to get a new team up-to-speed, and dev work already started with detailed plans of what to do next. Project Redshift can provide a user-friendly platform to kdb+ users. It combines kdb+’s ability to process large amounts of data in a very short space of time, with the flexible, scalable, and cheaper storage of historical data in Amazon’s cloud, providing an excellent option for users interested in integrating cloud storage with their real-time data.
Share this:















