Gary Davies
Day 1
Themes of the day are scalability, availability and accessibility as we look to extract knowledge and gain value from our time series data

Key Note: Ashok Reddy KX

Following a brisk walk to the Montauk Lighthouse, Ashok Reddy took to the stage for an incredible keynote focusing on Knowledge Xtraction through their current and upcoming product suite. There was a nice cameo for the new Data Intellect logo as partner of KX. While Visual Studio for Q will open productivity for Devs and is nice to have, the announcement of kdb.ai and finspace will change the state of play. kdb.ai bringing a new dimension onto the kdb+ solution as an AI suite.

Partner Keynote: Tim Griesbach AWS
Finspace was a teaser into the partner key note as Tim Griesbach took to the stage to talk about the Amazon Web Services (AWS) partnered solution with Finspace and Managed KX Insights (general availability June). Be prepared to setup, operate and scale kdb with just a few clicks. The ability to launch and deliver on demand without the usual operational overhead is going to vastly reduce time to market. I think the phrase just became Watch this Finspace.
4 X kdb+ Use Cases
We then entered a phase with quadruple kdb+ use-cases as Citadel, Alex Donohue, Erin Stanton and Kevin Webster took to presenting.
Citadel took us through real time event processing and the integration of python into their kdb+ QF.
Kevin gave a financial analytics lesson as he presented on Price Impact, the reaction to order flow imbalance and how kdb+ makes this efficient, fast and possible.
Erin lit up the stage with an energetic presentation focusing on the advantages of data science powered by a clean, accessible dataset only possible by kdb+ in the backend. A world where focus can be less on the cleansing and access sounded like a blissful oasis as Erin can deliver value on the data.
Alex in his session continued on the python theme looking at how it is leveraged and presented an interesting look at comparing kdb+ and python, and how they are positioned in terms of roles in finance.
Data Intellect Presentation: Jonny Press

It was then time for our CTO Jonny Press to take to the stage. This marked the first and only round of applause for the slide transition of the day. Jonny presented the key data challenges that Data Intellect faces, and asked Connor Gervin to take these and tell us how KX’s new solutions will address. This resulted in a resounding challenge accepted from KX
KX qGods: Whats coming next
The final talk of the day came from Andrew Wilson and Pierre Kovalev. This took us into the world of core at KX as we got to hear about what’s coming before the brave Pierre live demo’d functionality, some of which is done, others on the way. Think pattern matching, new dictionary definitions, more error handling, .Q.lo, nanos populated, and my favourite \c 0n 0n for that auto workspace resizing.
Day 2
2 big announcements to start which are now publicly shared; PYKX is now open, and KX integration partnership with Snowflake.
Snowflake Partnership
Snowflake representative Jeff Lee opened the day with a look at the early integration using snowpack as part of their disrupt app development strategy. This could provide an exciting opportunity for clients with data in both technologies (including PYKX) and that’s set to snowball further as KX looks to integrate PYKX with anaconda making it even simpler.

Speed Mentoring?
Next it was back to kdb+, or was it, as qGods and qBies entered what appeared to be a speed dating approach to mentorship…but no this was an interactive example from Nick Psaris, CFA as 20 “volunteers” were using as part of his talk on matching algos in q. From here he demonstrated q code and walked through the stable marriage and roommate problems amongst others. This highlighted some interesting algos including ones that fed into kidney matching and became the perfect segue into talk 3.
kdb+ in Health Space
Syneos health stepped up with Nataraj Dasgupta showcasing how kdb+ has disrupted data solutions in the health space and provides fast and efficient analysis. A great set of figures showcase kdb+ as solving an issue in 5 minutes in the cloud for 50 cents, beating it’s other data technology substantially coming in at 125 minutes and 50 dollars.
Crypto
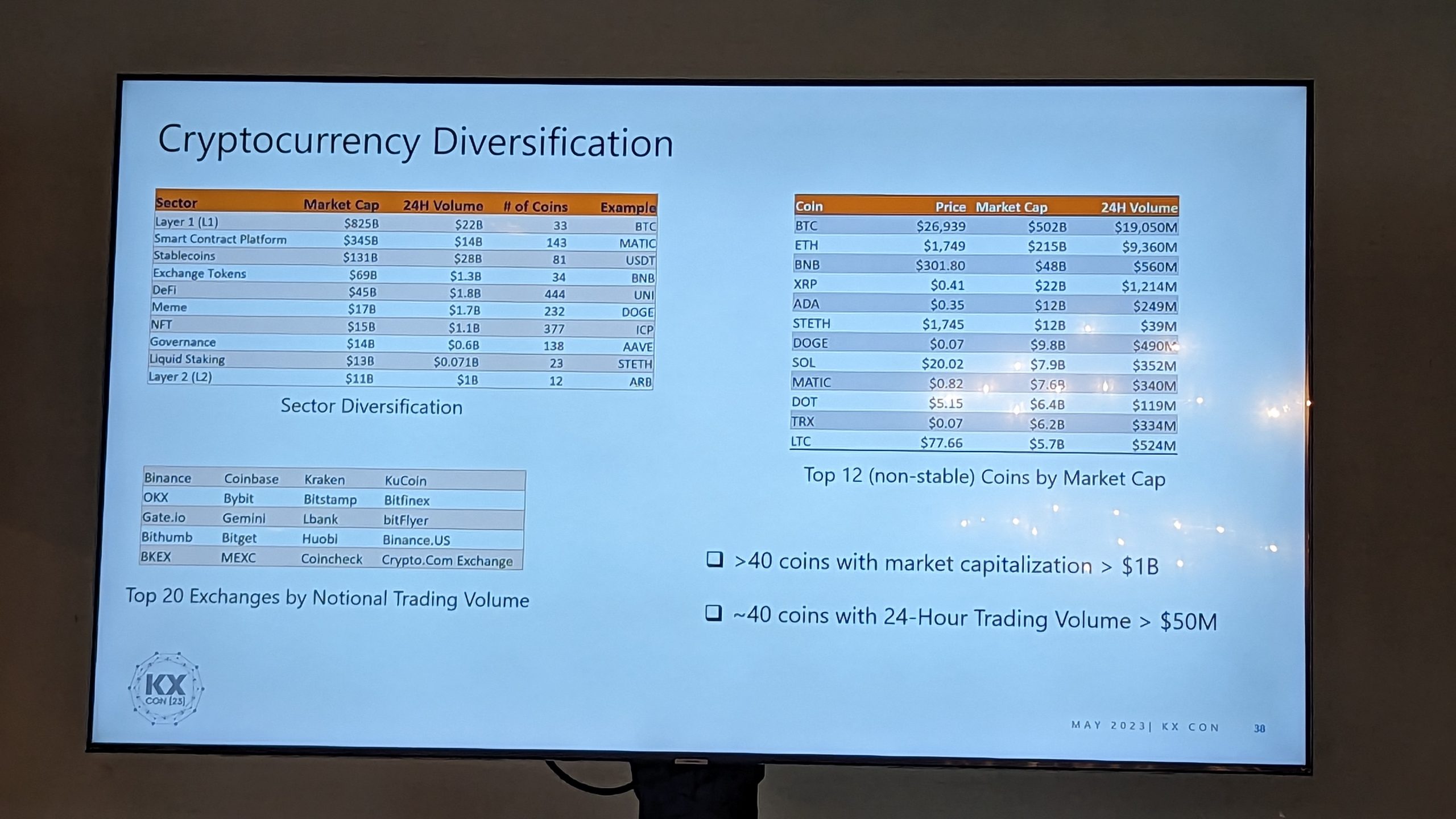
XBTO took to the stage first and had a shout out for both TorQ and Data Intellects Jonny Press. Zakariyya Oudrhiri took the stage second and talked through crypto and took us into the potential world of kdb+ and Blockchain. Finally we got an introduction into the world of StratMaker.
Using kdb+
After lunch we had Phineas showing us how to do image resizing in q, before Igor took to the stage to talk data engineering and the key characteristics around that.
inqdata then took us through a potential interactive bot called qbot with knowledge of querying and market data.
Aaron Davies was up next with a great look at the T in chatGPT and introduced us to his RASPq. This is a blog worth checking out as it walks through the transformer algos in q.
Conor Hoekstra from NVIDIA stepped up to the plate and challenged Erin from yesterday on most energetic presentation of the event. We got an interactive q solving session and a challenge laid out for a kdb+ logo?
The talks ended with STAC presenting on how M3 volcano named tests work and was a good way to remind us all that kdb+ is still, after all these years, FAST!
Ashok Reddy brought the conference aspect to a close as we ended what has been a fantastic event. Full kudos to KX incl. James Corcoran for putting on a fantastic event.
My takeaway from this is, KX is evolving and it's going to be supercharged through interoperability, cloud-ability and improved usability
Share this: