TorQ Segmented Tickerplant
Elliot Tennison
Our most recent project here at AquaQ Analytics has been an extension of the TorQ production framework. In particular, a new segmented tickerplant process (STP) has been incorporated into TorQ which will provide greater flexibility to the user whilst also preserving the functionality of the original tickerplant process. This blog post will revisit the role of the tickerplant in TorQ, show the new features that a segmented tickerplant provides and highlight the advantages of its inclusion into the framework.
TorQ Tickerplant
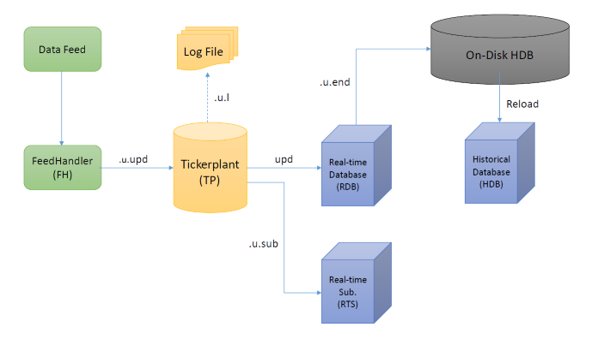
Within a data capture system, the tickerplant process is vital. The original TorQ tickerplant is the kdb+tick tickerplant with some minor modifications. The tickerplant provides an entry point for data into the framework, timestamps the incoming data and then publishes the data to its subscribing processes. The tickerplant also produces log files which capture the data moving through the tickerplant. These may be replayed to catch up a subscriber should it lose connection or die. Figure 1 shows an example process architecture and illustrates the tickerplant’s place in the framework.
The current tickerplant is very efficient. The aim of this project was to provide a more customisable and user-friendly process, especially regarding logging and subscription.
Segmented Tickerplant
Firstly, the functionality of the STP is fully backwardly compatible with only a few minor (and we believe seldom utilised) exceptions. The new features that the segmented tickerplant introduces are listed below.
- the ability to create more granular log files
- a new batch publication mode
- the ability to easily introduce custom table modifications upon message receipt
- more flexible subscriptions
- error handling for easier debugging when developing data feeds
- performance improvements for several use cases
All the TorQ based subscriber processes (e.g. RDB and WDB), and any subscribers that use the TorQ subscription library, can switch between the original TP and STP.
We will start by examining the new STP logging modes.
Logging Modes
With the current tickerplant, an entire day of data is logged to a single log file. In some cases, the log files can become very large, making them more difficult to manage. Instead, the STP generates a directory of smaller log files for each day. This allows data to be prioritised insofar that irrelevant log files may be ignored during a replay. For example, if a process is not subscribed to a particular table, it is not required to replay the records of that table.
The specific logging behaviour of the STP can be controlled with the following logging modes.
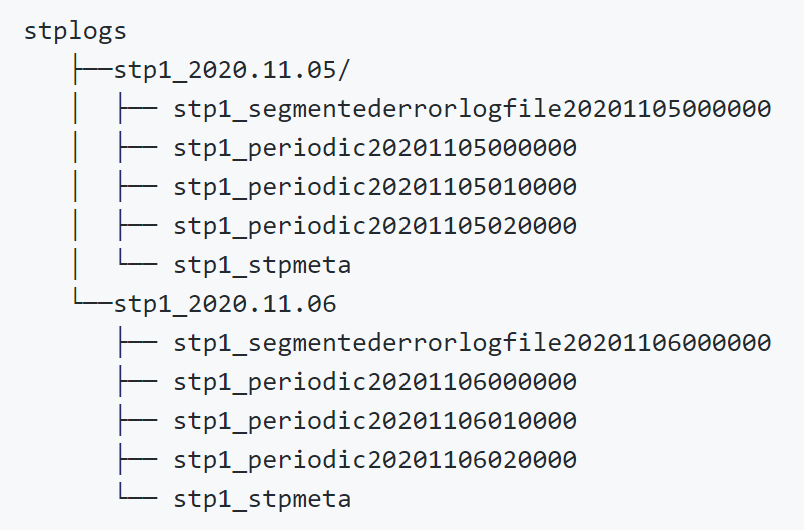
Periodic Mode: In periodic mode, the logs are rolled on the basis of a user-specified period of time. This has the effect of breaking the log files into smaller sizes and potentially allowing for easier management. This also maintains the message arrival order during replays, similar to the original log file format. Figure 2 below shows the file structure of the logs when the user-specified period is equal to one hour. Note here that the error log files are included as well. These files contain any bad messages moving through the STP that have been caught by the STP error trap.
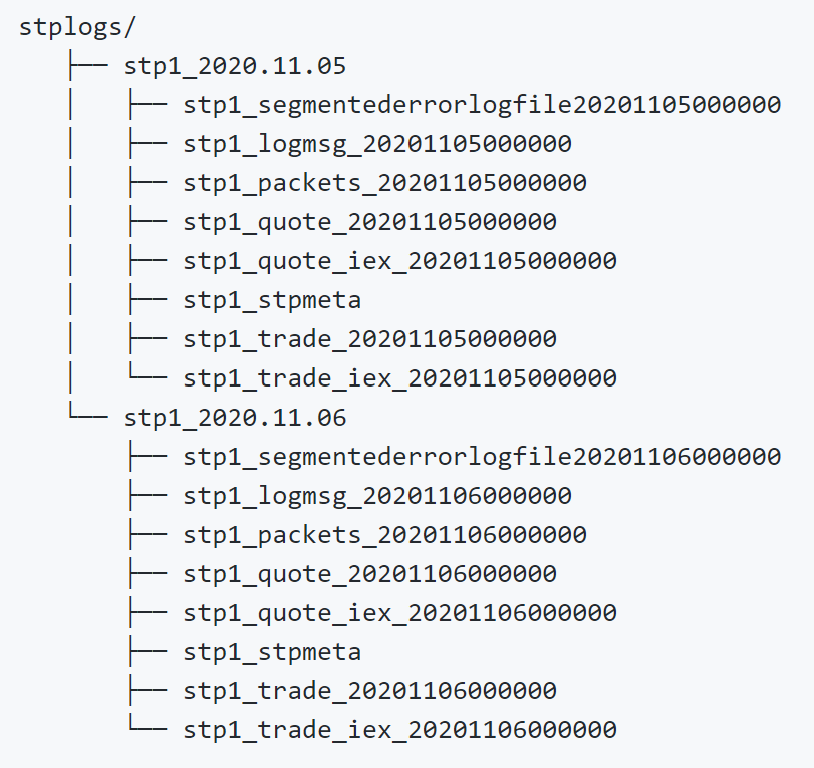
Tabular Mode: Instead of partitioning the logs with respect to time like periodic mode, tabular mode splits the log files by table. The log file for each table is then rolled at the end of each day, much like the tickerplant’s default mode. In other words, the log file for each table is closed and a new one is opened for each table for the next day. Figure 3 below show the resultant log file structure of this mode.
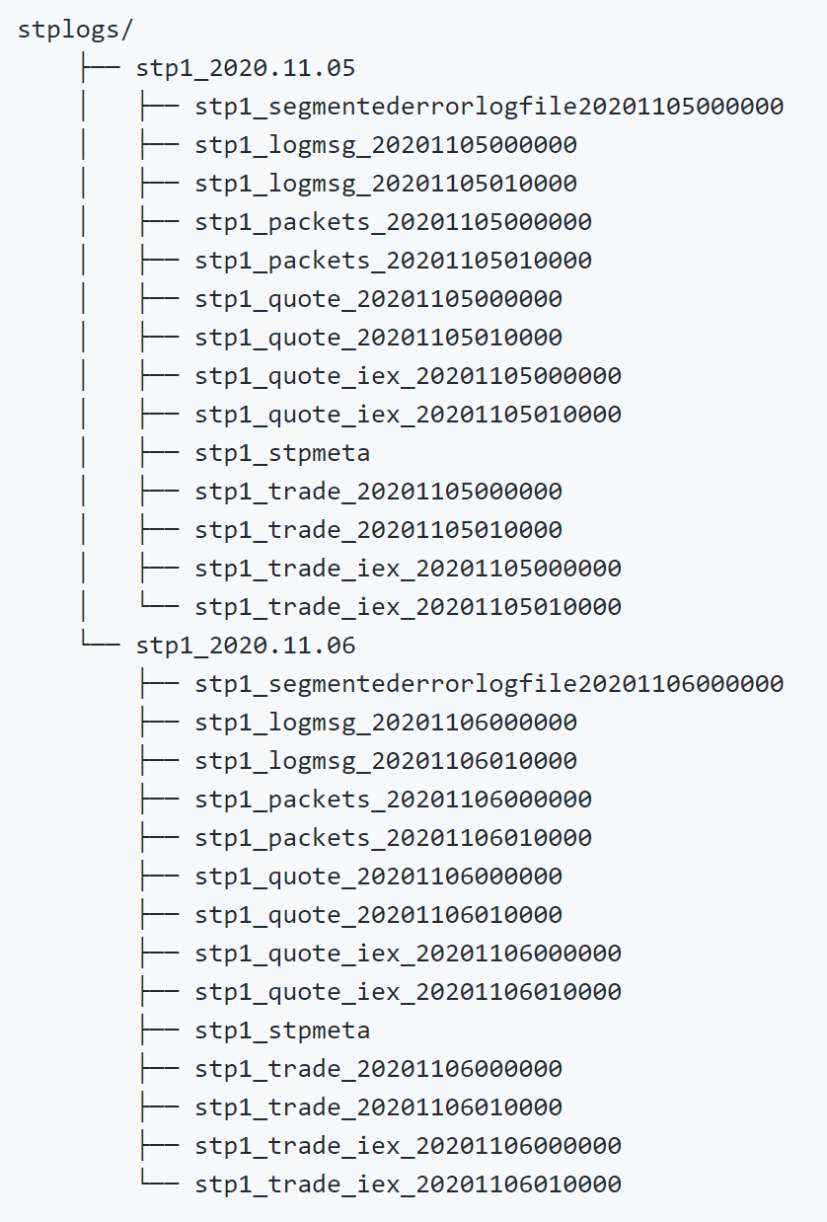
Tabperiod Mode: As the name suggests, this mode combines the behaviour of the tabular and periodic logging modes. Each table has a dedicated log file which is rolled at the end of each user-specified period. This adds the flexibility of both those modes when it comes to replays. An example of the log directory of this mode is displayed in Figure 4.
Custom Mode: For even more control over how each table is logged, custom mode allows the user to assign individual logging modes to each table. This mode is particularly useful if one table is receiving considerably more updates than another.
Singular: In the spirit of backward compatibility, singular mode can also be used which is essentially the default TP behaviour. Here all ticks across all tables for a given day are stored in a single file.
These new logging modes provide varying degrees of flexibility in the structure of the tickerplant logs. The variety of options also mean that the granularity of the logs may be tailored closely with the needs of the user.
Batching Modes
Along with new logging modes, the segmented tickerplant also introduces a series of new batching modes. These new batching modes allow the user to be flexible with process latency and throughput:
Defaultbatch: This is effectively the standard tickerplant batching mode where, upon receiving a tick, the STP immediately logs it to disk. The update is then added to a batch which is published to subscribers whenever the timer function is next called. This mode represents a good balance of latency and overall throughput.
Immediate: In immediate mode, no batching occurs. Updates are logged and published immediately upon entering the STP. This is less efficient in terms of overall throughput but ensures lower latency.
Memorybatch: In this mode, neither logging nor publishing happens immediately but everything is held in memory until the timer function is called, at which point the update is logged and published. High overall message throughput is possible with this mode, but there is a risk that some messages aren’t logged in the case of STP failure. Also note that the ordering of messages from different tables in the log file will not align with arrival order.
Subscription
Instead of being able to filter only for the tables and symbols a subscriber needs, the STP gives subscribers much greater control over the data they receive. For subscription, processes may still subscribe as they did with the original tickerplant. However, there are two new methods. First, a process may subscribe such that a condition on the data values is satisfied. Second, subscribers have the option of receiving a particular subset of columns for a table.
First, incoming data may be rejected by a subscriber on the basis of the data itself. Here the filtering works much like a where clause used in qSQL. For example, a subscriber may only want to receive quote records where bid > 30 and trade records for a particular exchange. These conditions may be applied to any column in any table the process is subscribed to. Additionally, the columns of records may also be filtered. This is useful when a subscriber only needs a particular set of columns from a very large table.
Now that the major features of the new segmented tickerplant have been outlined, we will demonstrate how to actually use it. An instance of the segmented tickerplant will be started and a process will subscribe using the new STP subscription features.
Subscription Demonstration
This demonstration assumes that the user has the latest versions of TorQ and TorQ-Finance-Starter-Pack. Use the TorQ installation script to install the latest release and follow along.
The STP process is set up to run in the TorQ Finance Starter Pack by default. Therefore the below terminal command will start the STP and all other TorQ processes. Ensure that you are in the deploy directory when running this.
bash torq.sh start allRun a summary to check that your segmented tickerplant is running correctly.
bash torq.sh summaryBy default, the RDB’s subscription to the STP is not filtered at all. In order to make it more complex, a csv file provides the additional subscription conditions. Create a csv file containing the lines below.
tabname,filts,columns
trade,"ex in ""N""","time,sym,ex"
quote,"bid>50.0","time,sym,bid,ask,bsize,asize"Under these conditions, the RDB will only receive time, sym and exchange data for trades on the NY exchange and will only receive a selection of quote columns where the bid price is larger than 50. To apply these conditions to the RDB, ensure that the subcsv variable in the appconfig/settings/rdb.q file contains the path to your csv.
subcsv: `:path/to/example.csvLooking at the records of each table in the RDB, we can see that the complex subscriptions have been successful. Although this example focused on the RDB, this subscription method may be applied to any TorQ subscriber.
q)rdbHandle"trade"
time sym ex
-------------------------------------
2020.11.25D11:46:29.261094000 AAPL N
2020.11.25D11:46:29.261094000 AMD N
2020.11.25D11:46:29.261094000 INTC N
..
q)rdbHandle"quote"
time sym bid ask bsize asize
------------------------------------------------------------
2020.11.23D00:00:01.054338000 GOOG 384.03 385.17 30 48
2020.11.23D00:00:01.054338000 AMD 72.13 73.32 70 64
2020.11.23D00:00:01.054338000 AMD 71.62 73.29 67 76
..Performance
In addition to providing flexibility, the STP also performs slightly better than the original tickerplant. Figure 5 shows the performance of a variety of tickerplants in different batching modes using average Messages Per Second (MPS’s). For most respective batch modes, the STP performance has improved over the original tickerplant.
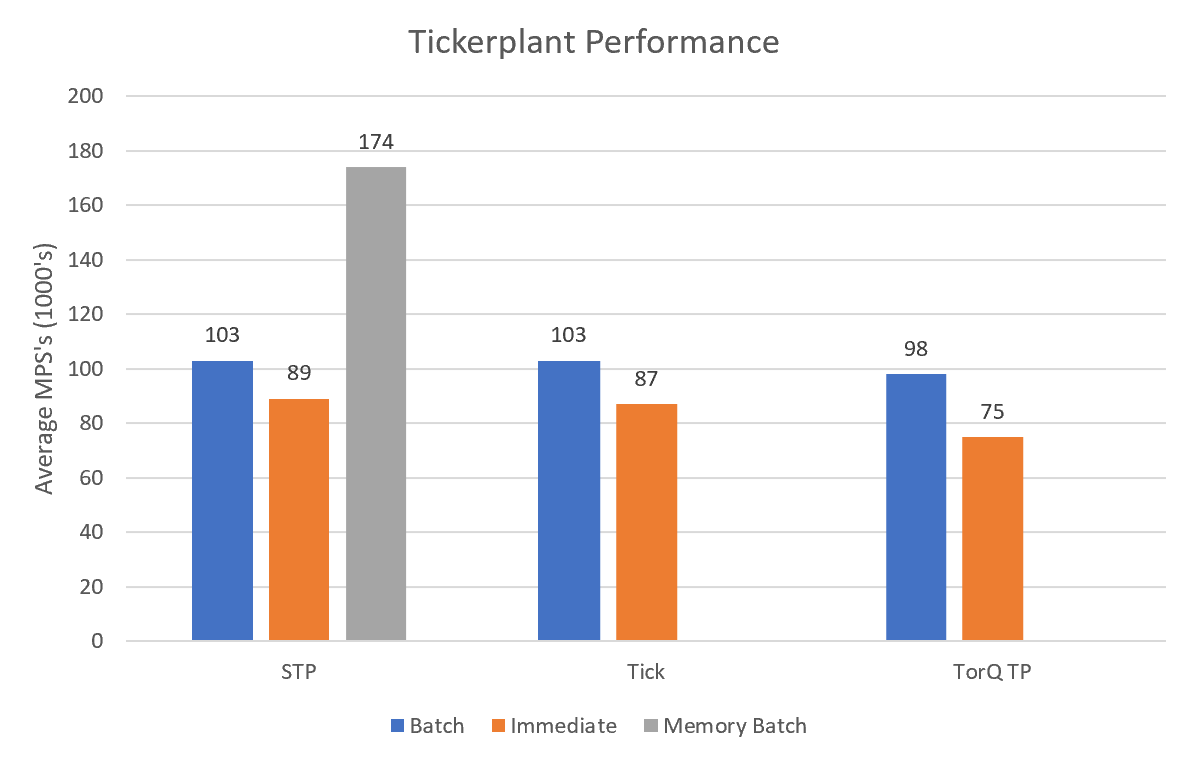
It should be noted here that the hardware used to produce the results in Figure 5 may not have been optimal for the given processes. Therefore, it is the relative values that should be focused on as opposed to the absolute figures.
Conclusion
It is clear to see that the new segmented tickerplant provides a range of new features that make the tickerplant a more flexible and user-friendly process. Moreover, the STP is also more efficient and performant.
There are even more features of the new STP that haven’t been outlined in this post. If you would like to find out more and have a full review of the process, please visit the process documentation. For more information on other AquaQ projects or if you have any questions, please get in touch.
Share this:















