Glen Smith
Instead of having a static infrastructure that is unresponsive to your changing usage, Google’s cloud platform enables the infrastructure to dynamically scale along with your usage. This means you only pay for what you are using, when you are using it.
We’ll create a simple proof of concept demonstrating this scaling behaviour when used with kdb+. This will utilize some simple bash scripts and the web console to complete the task. How to manage deployments using the deployment manager and containers is outside the scope of this post.
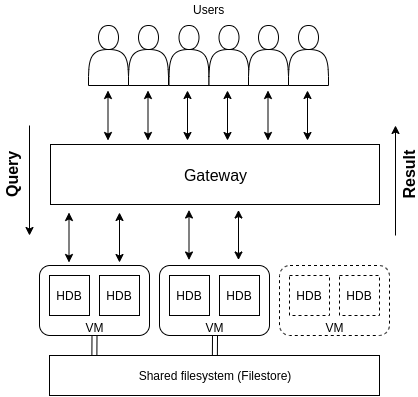
The HDB (Historical Database) is an on disk database that is used to provide access to data that is no longer held in memory e.g. the previous day’s data in a real time capture setup. Multiple HDBs using the same on disk data can be running simultaneously so that incoming queries can be executed across the group concurrently. A gateway is a process that serves queries to the HDBs providing the user with one entry point and abstracting away any load balancing or server connection logic. This is analogous to the load balancing pattern seen in web application architectures with a load balancer and cluster of web servers behind it.
For demonstration, VM instances with less resources are used instead of one monolithic instance. Our architecture will consist of the TorQ discovery, gateway and a group of HDB processes. The discovery process is there to keep track of the newly created HDB processes and the gateway will allow seamless querying across them.
To set this up we’ll be using the cloud console and the gcloud command line tool for interacting with the instances.
Data storage – Cloud Filestore
Data will be stored on Cloud Filestore, a fully managed NAS filesystem that can be mounted to multiple VMs. For our managed instance group, the filestore will be mounted as read only. For this demo I uploaded the HDB data separately.
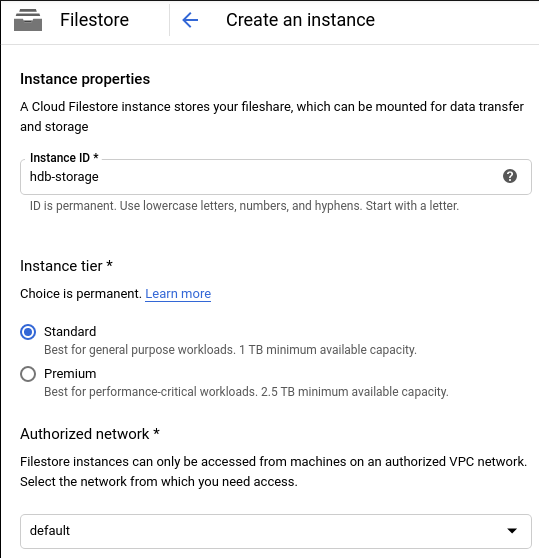
Create the fileshare in the same zone as the rest of the project.

How do we scale?
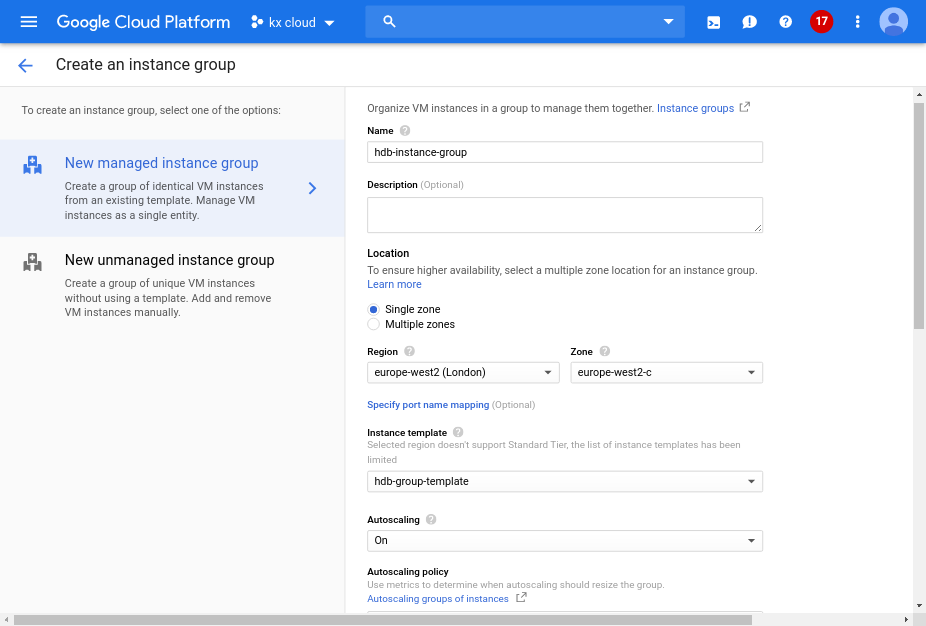
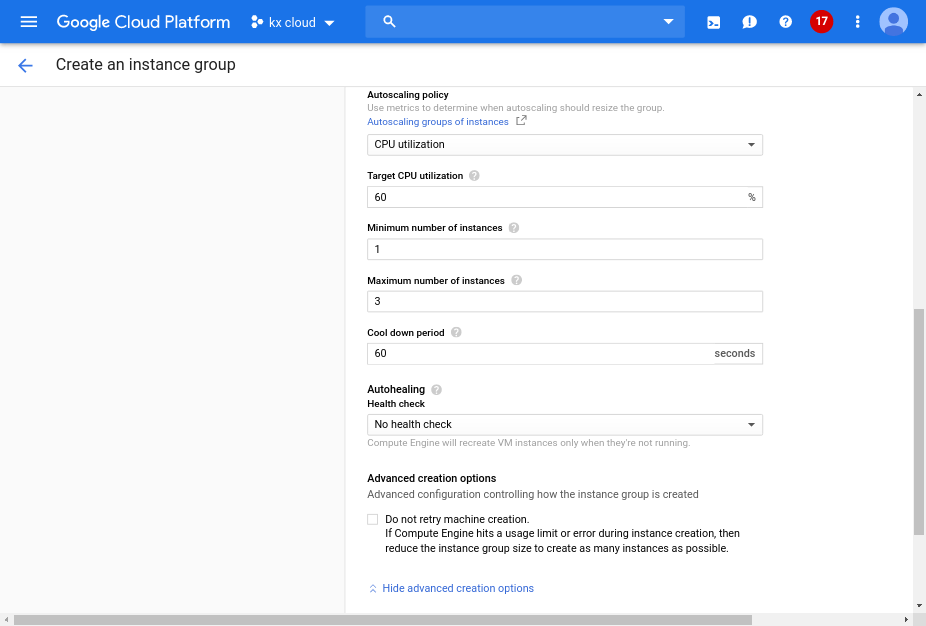
Google Cloud provides functionality to autoscale a group of instances, called a managed instance group. The instances are based on a template which we will create. More instances are added to the group depending on a metric e.g. CPU utilization. This approach means that a group with a single HDB instance can scale up to as many HDB instances as required based on the scaling metric. The scaling metric is also used to scale down the group if it falls below the predefined threshold meaning those previously created additional instances will begin to shut down.
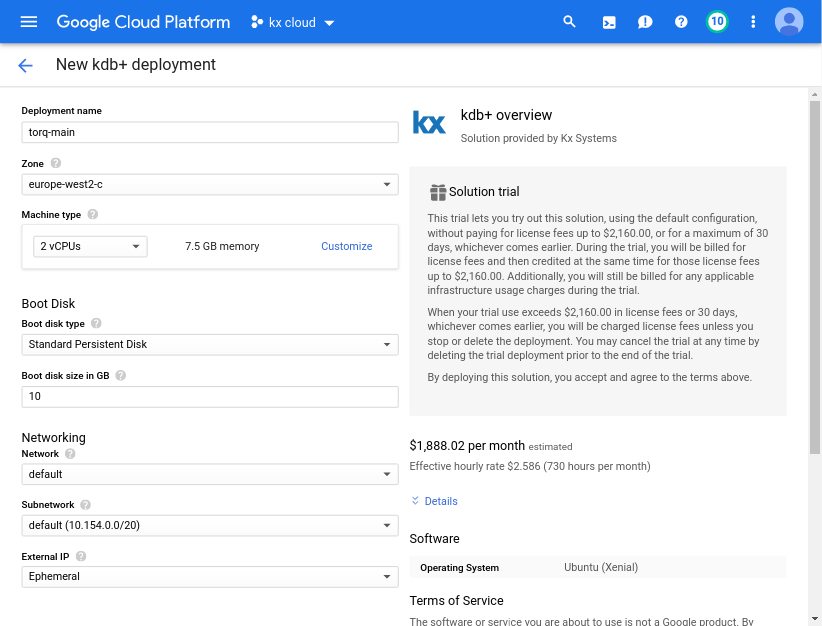
Create a VM instance for the discovery and gateway processes
First we’ll create a VM instance using the kdb+ item in the marketplace. We’ll use the n1-standard-2 (2 vCPUs, 7.5 GB memory) machine type as this will be the machine type our HDBs will use. Make sure that your VMs are in the same zone throughout.
Create the scaling instance template
A template can be created from an existing VM instance so we’ll use the same VM we just created. Stop the instance before the template command is executed. We can quickly add metadata to it before we create a template based on it. This metadata is later removed. It includes our start script which contains commands to mount the Filestore and then start the TorQ HDB process. For ease of use I uploaded the start script and the deploy script to a separate Google cloud storage bucket. The scripts can be found in our utilities repo.
# add metadata scripts to stopped instance
gcloud compute instances add-metadata torq-main-vm --zone europe-west2-c --metadata startup-script-url=gs://torqdeployment/hdb_mig_start.sh
# create an instance template
gcloud compute instance-templates create hdb-group-template --source-instance torq-main-vm --source-instance-zone europe-west2-c --region europe-west2-c --tags hdb --no-address
# remove metadata from the stopped instance
gcloud compute instances remove-metadata torq-main-vm --zone=europe-west2-c --keys=startup-script-url
We can now create an instance group based on the template we have created. This is where we configure the autoscaling features by specifying the parameter thresholds (eg. CPU utilization) and also number of instances to add.
The managed instance group has now been created and the first instance of the group is deployed immediately. The hostname of each new instance is assigned with a 4 random character suffix. The other torq-main-vm can now be restarted.
The log output can be seen on the VM instance page. This shows the output of the initialization process including our start script logs. TorQ is now deployed in the user’s home directory under the release folder.

Once the script completes and the HDB process is launched, it will become available to the gateway and appear in the .servers.SERVERS table.
Simulating heavy usage
The HDB group is being monitored for CPU utilization and therefore to demonstrate scaling it is necessary to simulate the instance under heavy load. This command is to be executed on one of the HDB instances which you can ssh into via the gcloud command.
# log into the hdb-instance-group-4s27 vm
gcloud compute ssh hdb-instance-group-4s27 --zone=europe-west2-c
# run this command to create heavy load on the CPUs
for i in $(seq $(nproc)); do
yes &>/dev/null &
doneIn order to see new instances being launched, periodically refresh the HDB instance group page. It takes approximately one minute for an instance to fully boot up; during this time the start script is being executed to deploy the TorQ code and start up the TorQ HDB instances.
Once these HDB instances have started they’ll connect to the discovery process which will make them known to the gateway. The below query result shows the startup delay between the new instances launched.
q)h"1_select deltas `time$startp from .servers.SERVERS where proctype=`hdb"
startp
------------
00:00:49.561
00:01:20.062We can start querying against the gateway and return which host was used for the query. The example below is to show the distribution of the queries sent to the gateway.
q)results:([] time:`time$();proc:`;result:`long$)
q)handleresults:{`results upsert (.z.t;;). y}
q)do[1000;(neg h)(`.gw.asyncexecjpt;({(.proc.procname;count select from trades where date=last date)};`);(),`hdb;raze;handleresults;0Wn)]
q)select querycount:count i by bucket:1 xbar time.second,proc from results
bucket proc | querycount
------------------------| ----------
15:42:58 hdb-scaled-2l3k| 105
15:42:58 hdb-scaled-8x5c| 104
15:42:58 hdb-scaled-4s27| 74
15:42:59 hdb-scaled-2l3k| 277
15:42:59 hdb-scaled-8x5c| 271
15:42:59 hdb-scaled-4s27| 169 From these results we can see that the “4s27” instance, which currently is under heavy simulated load, is unable to run as many queries as the others. The other scaled instances are now helping with the workload.
If you are working with kdb+ TorQ, we welcome your feedback for future development so please get in touch!
Share this:















