TorQ 2.0 Released
Data Intellect
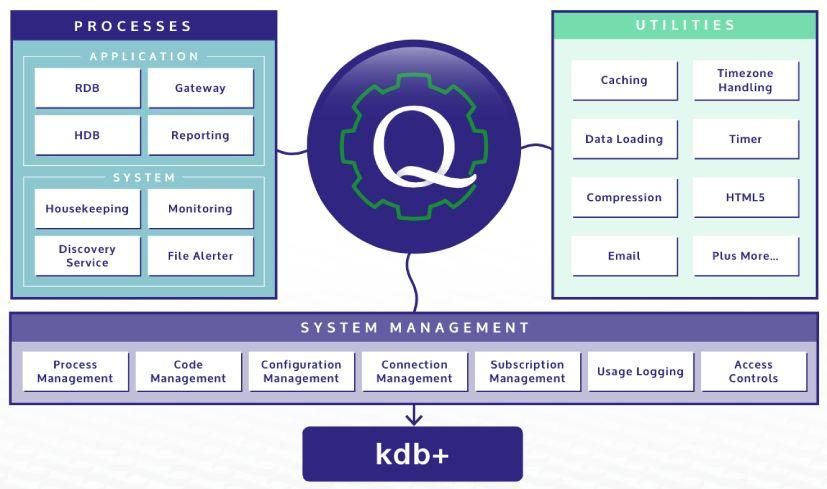
We are proud to release version 2.0 of TorQ with some big functionality extensions. The changes have stemmed from community feedback, customer installations and just what we thought would be nice to do. You can download it here. Enhancements include:
- new RDB (real time database) and WDB (writing database) processes. These provide significant system architecture flexibility and can be used in combination with kdb+tick to produce a data capture system without an end-of-day data outage, and no tickerplant “back pressure” when data is persisted to disk (see here for more details)
- easier deployment of TorQ across hosts or port ranges
- an email lib to distribute emails from q processes
- a reporting process which can be used to run scheduled reports throughout the week. The report results (e.g. csv, xls etc.) can be written to disk, sent over email etc.
- a set of standard monitoring checks to detect common failures in a data capture system, such as failure to persist data to disk, the stream of updates stopping, and slow consumer problems. These can be run from the reporting process with alert emails generated as required.
- a -localtime flag which will make TorQ run in local time rather than GMT – log messages will be printed with local time, timers run in local time etc.
- a set of data loading utility functions to help load large data files to disk
- tickerplant log recovery utilities allowing all the good records in a corrupt tickerplant log file to be recovered, rather than just all the messages before the first bad one which is the current approach (more on that here)
- subscription management code to ensure processes are correctly subscribed to required data sources
- some fixes for running on 2.* and 3.* versions of kdb+
In the previous release of TorQ we had some example application code mixed in with the core application code. With this release we’ve stripped out the example parts and instead created a Starter Pack which will allow easy set up of an example market data capture system- just install the Starter Pack over the top of the core package. Our Finance Starter Pack includes a sample feed handler (derived from here) and has a few things to have a play with (see the document for more details). It will run on Windows, OS X or Linux.
Setting up a baseline data capture system with TorQ should now be very simple: install TorQ, install the Starter Pack, switch out the feed and schema for your specific implementation and off you go! If however you would like some help with architecture considerations, set up and support, please contact us to discuss the options.
We’ve switched the code base from code.kx.com to Github – we intend to use Github as the primary development repository for TorQ. Feel free to contribute back!
What’s Next Then?
In future versions of TorQ we plan to incorporate:
- Gateway enhancements to allow query routing logic to be driven by request parameters. Instead of a client specifying which processes it needs to access, it will be able to specify the attributes of the data it requires and the gateway will work out the optimal route for accessing that data. This is useful where different data sets are striped across databases, by time range, key field etc.
- A Chained Tickerplant process
- Integration with MMonit to allow the system to be monitored and processes automatically restarted etc.
- Integration with LogStash to allow a centralized visualisation of log file messages and query activity on back end processes
- Release of a BetFair Starter Pack to allow people to capture, store and analyze data from Betfair (i.e. the system we’ve been using for our betting blogs)
Any feedback or enhancement requests would be greatly received. We will be hosting a webinar on TorQ in June. And let us know if you want any training!
Share this:















