Gary Davies
There has been a trend in recent years to move towards containerisation in software solutions. A containerised approach looks to package applications along with their dependencies for ease of deployment and improving scalability and resiliency.
AquaQ has created a proof of concept which looks at leveraging containers, in conjunction with kdb+, to demonstrate the following capabilities:
- Use of kdb+ in a containerised solution
- Application of entitlements in a kdb+ containerised solution
- Integration of kdb+ containers within a typical data publisher setup
The system modelled by this proof of concept simulates the flow of equities trade and quote data from publisher through to permissioned end users.
This blog will discuss the architecture, execution and conclusions from this successful implementation.
Architecture
A typical setup from publisher to end user for market data would comprise the following: feed, messaging layer, feedhandler (FH), tickerplant (TP) and real-time database (RDB). These elements, at a high level, provide data creation, distribution, conversion, recovery and visualisation
In the AquaQ proof of concept the architecture is defined as below
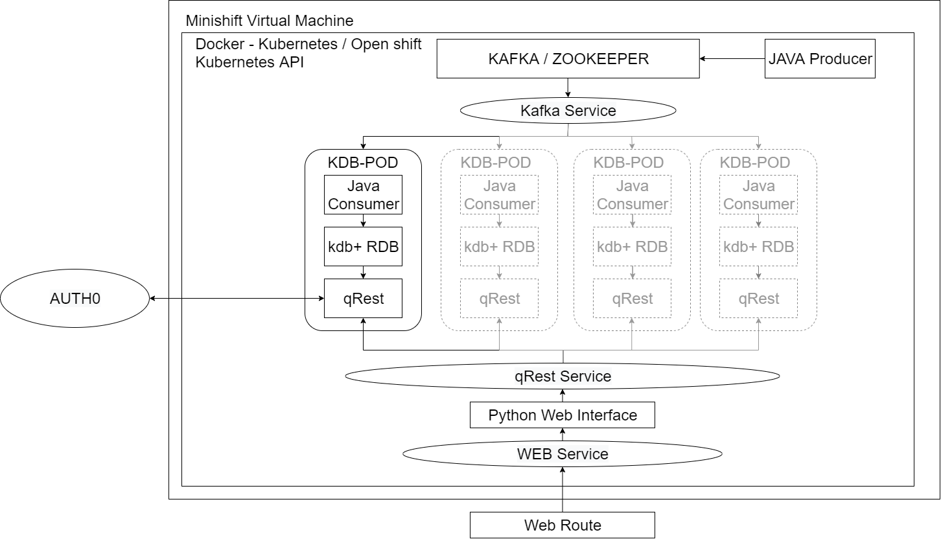
The solution runs on a Minishift virtual machine which runs a full OKD Cluster (Openshift Kubernetes Docker) to provide containers and container management.
As with the typical setup the architecture requires a data feed/producer and messaging layer. These are achieved in the container solution by 2 containers; Java producer and Kafka/Zookeeper. Kafka is leveraged here as it provides a scalable messaging layer with data recovery. These containers provide the data creation, distribution and recovery functionality.
Downstream of this is our scalable KDB-POD which is used for our real-time data capture. In the typical setup this would be the FH, TP and RDB. The TP is what provides the recovery mechanism in a kdb tick setup whereas in this architecture recovery will be managed through Kafka. This allows us to remove the tickerplant from the equation and with good reason. The tickerplant recovery mechanism involves persisting the messages to a log file on disk. This creates a dependency on the disk and the log which can make it difficult to scale and also means our pods would need to have access to disk. Removing the TP means there is no interaction with disk and no shared space or cross dependency between pods. Our KDB-POD, therefore, houses the Java consumer (FH), RDB and q-REST containers. The q-REST container is included here as it will provide us a means to constrain what users can see and do.
q-REST is an open source restful interface provided by AquaQ and can be found on github. The version leveraged here has been modified to handle tokens for our entitlements element of the proof of concept.
Entitlements and role management is provided through Auth0 in this architecture which allows us to simulate a single-sign on. The q-REST API is capable of calling out to Auth0 to enable it to apply the appropriate level of controls.
The KDB-POD has only a single entry point, through one port to the q-REST API. This ensures that the kdb+ RDB process is non-contactable by hopens or web requests preventing unauthorised access.
The containerised solution is accessible through a python based web front-end which routes into the containerised solution and is directed to an available pod via q-REST.
Entitlements: Roles
A key element of this proof of concept is to demonstrate entitlements application to a kdb+ containerised solution and for this we created a number of roles in Auth0 and applied them to demo users. All access is read only with q-REST API and the web-interface preventing update and system commands.
| User | Role(s) | Description | Demonstrating |
| demo0 | realtime | Full access to all data in real-time. | Superuser |
| demo1 | delay_15 | Access to data >=15 minutes old | Time filtering |
| demo2 | delay_05, xlon | Access to London data >=5 minutes old | Time and Row filtering |
| demo3 | delay_05, xams, xmil | Access to Amsterdam and Milan data >= 5 minutes old | Time and multiple row filtering |
| demo4 | no_ex | User is not able to see exchange data columns | Column filtering |
| demo5 | no_trade | User is not able to see the trade table | Table filtering |
The images below demonstrate the user demo2 implementation within Auth0.
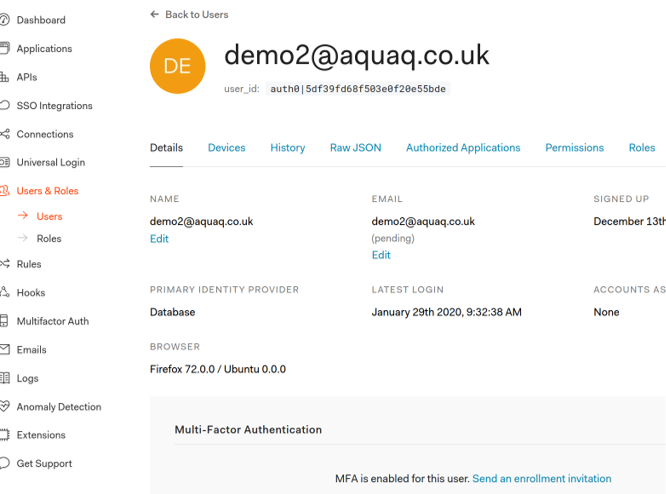
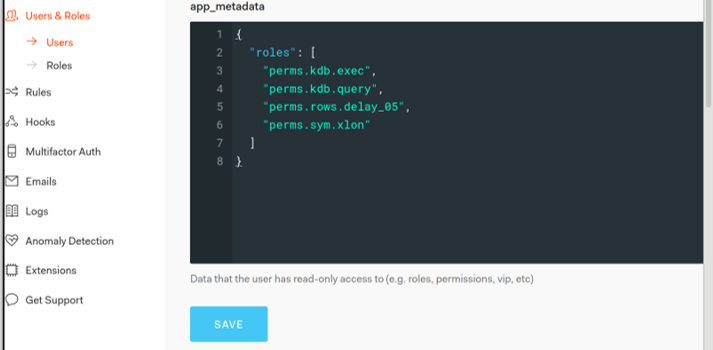
Solution in Action
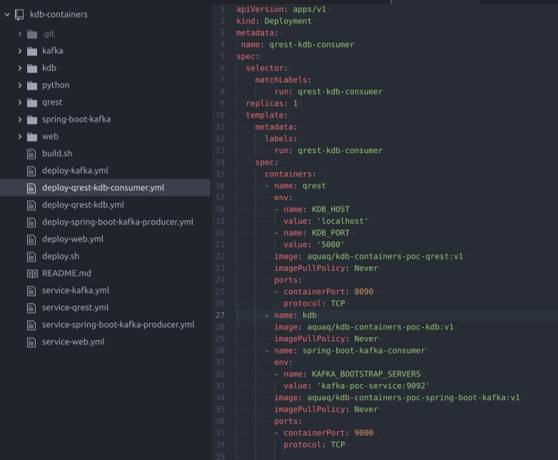
The build and deployment processes, in the containerised solution, are controlled through the .yml file(s), an example of which is depicted below.
The OKD interface shows all deployments, in the proof of concept there are 4; qrest-kdb-consumer (KDB-POD), spring-boot-kafka-producer (Java Producer) , web and kakfa.
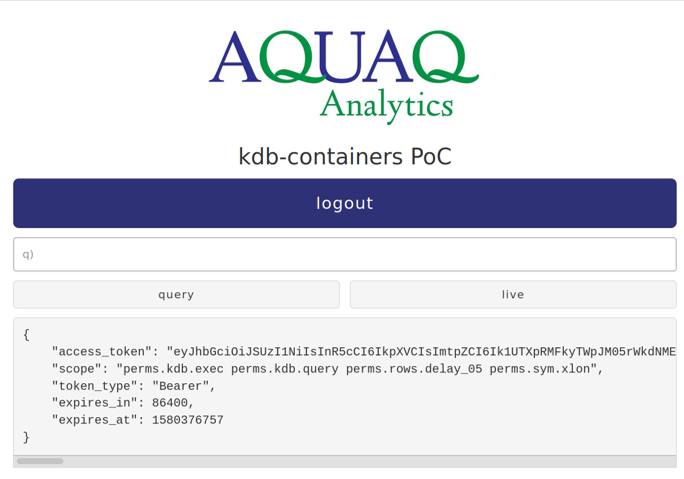
Users are presented with the AquaQ Login screen as follows.

Upon logging in the user is presented with a query box for which they can input freeform, read-only, queries. Results of queries are returned in the dark grey box. Initially this is filled with details on their access token and roles. Note that this is for demonstration purposes only and is shown below for example user demo2
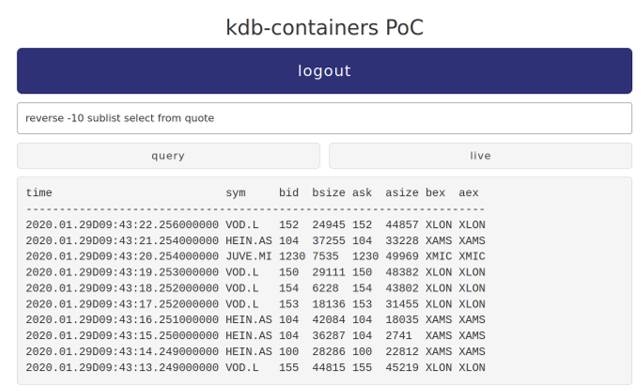
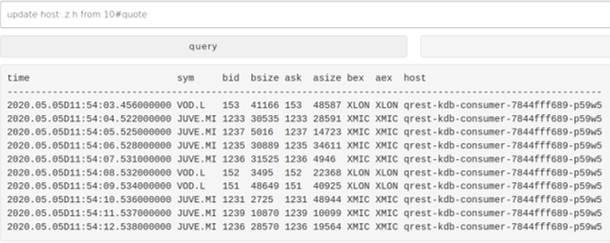
Users have the opportunity to choose from 2 types of query; query and live. Query is a single execution against the database, while live polls the data set every 500ms and updates the result.
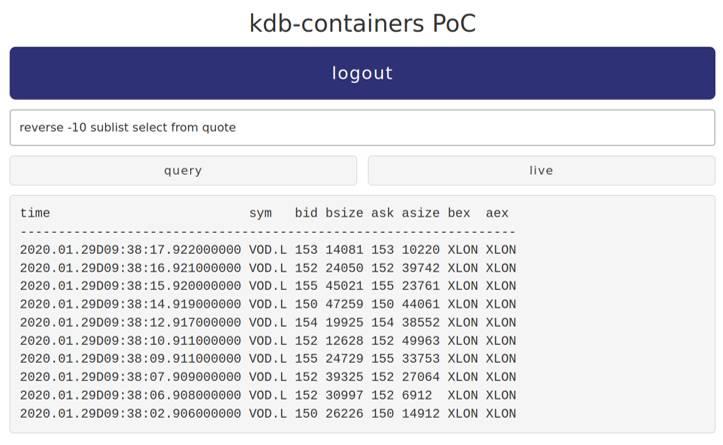
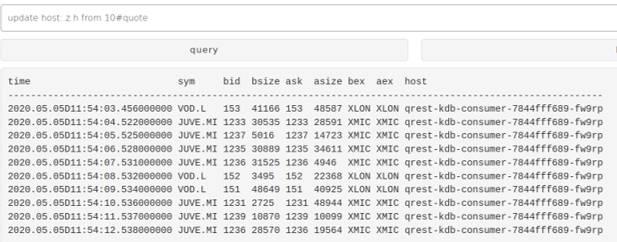
The below images depict 2 different users executing queries with varying permissions. demo0, is the first image, with full permissions to the data, showing quote for multiple exchanges live. The second shows demo2, with only permissions to London data more than 5 minutes old. Looking at the timestamps these are 5 minutes previous to the first image and only Vodafones London line is shown.
The queries are executed against available pods which can be scaled up as necessary. The solution has a required number of pods which is set at 1. This means that on launch a pod is automatically created and should anything happen to it the pod will be restarted.
As part of the proof of concept, a scenario demonstrating pod failure was created using a query that caused the memory usage to exceed 1GB, the configured limit for the pod. Upon reaching 1GB the pod was automatically killed and restarted. It should be noted that it was decided that such a scenario would not result in all data being replayed to that point as it is assumed that if there was an issue with the current pod it may force the system into a cycle of killing and restarting. This, however, is configurable.
It is possible to scale up, and down, the number of pods through the OKD interface which will automatically start up a new pod replaying the data from the Kafka layer. This scenario allows for a replay from start as its assumed the system is being scaled up to meet demand, again this is configurable.
The image below shows the interface for scaling with up and down arrows for application. In the scenario demonstrated the pods are being scaled from 1 up to 3.
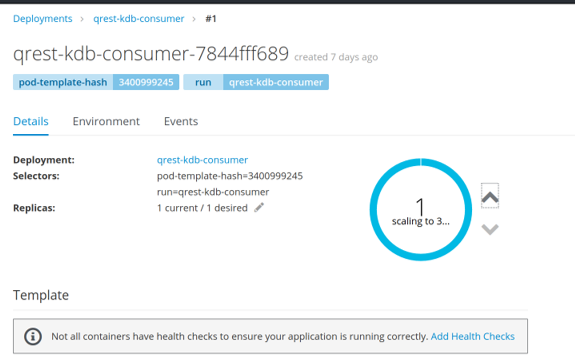
Once scaling is selected the pods are visible in the application as they are being created along side their host name. Remember each pod is comprised of 3 containers and this is where the “0/3” containers ready status comes from.
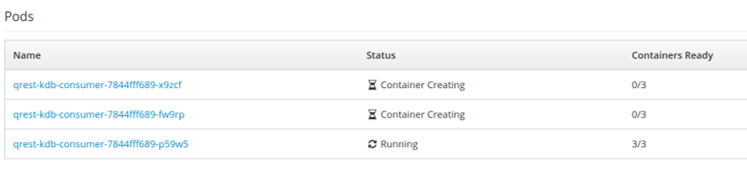
Once scaled up the number of pods will be visible as 3 and they will be marked as running.
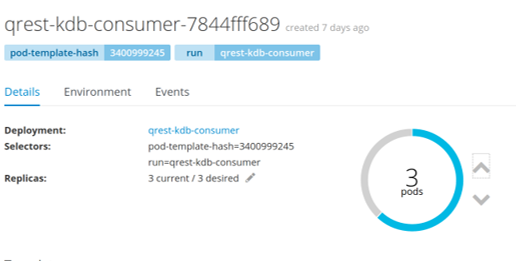

The front end can then have a query applied to it to show that queries are now routed across the pods. The next 2 images show the same query being executed with the host appended to the table. The host has changed between the queries and matches different names of the pods that were shown above.
Conclusion and future considerations
The proof of concept created was capable of demonstrating a simulated pub-sub setup on a containerised solution housing kdb+. The solution was capable of controlling user authentication and visualisation and created a scalable, resilient concept of kdb+ real-time pods. Comparing the containerised solution against the typical setup;
Architecture
- Potential to simplify through the removal of the tickerplant
- Replay functionality comes from the Kafka messaging layer
- Data consumption moves to being directly from Kafka as opposed to kdb+ to kdb+ subscriptions
- Current implementations would need to be reviewed and redefined.
Resources
- Reduced CPU consumption due to tickerplant removal
- Reduced disk usage due to no tickerplant log
- No disk dependency for the pods meaning they can scale horizontally easily
- Memory footprint of the RDB remains the same
Scalability
- q-REST provides a single entry point to access all available pods
- Pods can be scaled for additional RDBs. This would require chained tickerplants and RDBs in the typical set up.
- Horizontal scaling does not require manual interaction or configuration
- Pod monitoring can ensure n number of pods are active with starting/re-starting automated. In typical architecture this would require another tool to be leveraged.
Security
- q-REST API provides a single entry point to interface with kdb+, this could be leveraged in either architecture
- Pods can be set up to have a single entry port which can point to the non-kdb+, q-REST solution meaning when scaled there is no additional security requirement on the new processes as they are not exposed externally
Recoverability
- Pods can be spawned easily and automatically without the need for user switching or manual intervention
- Recovery time will still be dependent on the amount of messages to consume and how they are being consumed.
The ability for the real-time pods to recover relies on their ability to replay the messages that had previously been received. This changed in the containerised architecture from being the tickerplant to Kafka. In the test scenarios it was noted that the replays are configurable in terms of batching and batch size so therefore can both be tweaked to meet requirements and improve speed and efficiency. However, a fair test on more substantial hardware, with increased messaging, would be needed to see whether the tickerplant or kafka replay would present better performance.
It is also worth noting here that the latest kdb+ release, which comes with Optane support, may open up the possibilities of a completely different recovery mechanism through memory over disk or logs.
The key consideration on progressing any containerised solution incorporating kdb+ is that it will force an architecture review of current kdb+ implementations.
This is demonstrated in the proof of concept by the removal of the tickerplant from the system in order to create a more lightweight solution with no inter-pod dependencies.
Following on from the proof of concept, the team considered how this might impact a theoretical, more complicated real-time architecture. This is depicted below.
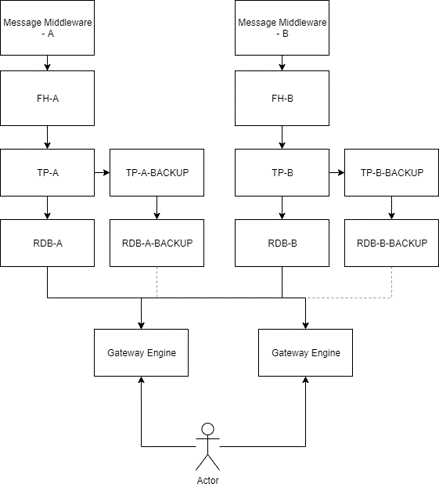
In this architecture, there are 2 different real-time tick setups running in parallel, both having disaster recovery through a chained setup. Both real-time databases feed a gateway engine that collates/processes the data and is accessible by end users.
In such a system the components are all individually managed and supported with potentially open access to different elements. For example clients could potentially access RDB-A, RDB-B or the engines. This means that any issue caused to RDB-A will impact its clients and Gateway Engine users.
Chained tickerplants also mean that there is a single point of failure that could impact all setups and require manual intervention or impose some form of data loss.
Maintaining and supporting this architecture requires supporting all the potential points of failure and manually intervening or writing something which actively monitors and applies actions based on issues. Migrating this system across servers or across kdb+ upgrades can be manaual and can require interaction across multiple elements and their clients.
Considering the proof of concept, the following architecture was defined as a potential alternative.
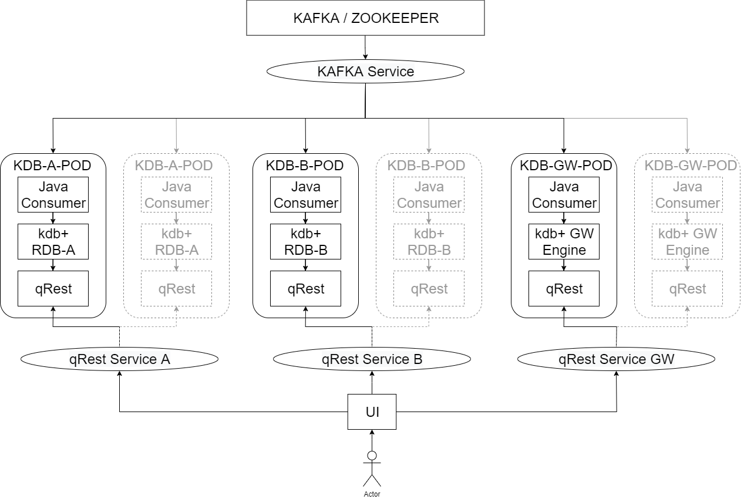
Each RDB has been converted into the scalable KDB-POD with no tickerplant and disaster recovery can be managed through maintaining multiple pods and supply and demand can be met by scaling up and down independently.
The gateway engine now subscribes directly to the Kafka layer taking in the datasets and processing accordingly. This removes the dependency on RDB-A and RDB-B while creating another scalable component to meet demand. This does of course mean that more memory would likely be required to house this architecture versus the typical one and thats something that should be considered and may impact the overall cost.
A user interface could be implemented in front of these directing clients to the appropriate dataset with entitlements managed through something like a modified q-REST API.
In this scenario the manual intervention is reduced as pods can be manged through openshift and free monitoring through prometheus and grafana. There is also the opportunity to integrate the latest kdb+ grafana adapter created by AquaQ. There is no open access to kdb+ processes with all pods having single entry points through the q-REST API. The solution becomes instantly scalable and migration is simplified due to no server specific configuration. It could also potentially ease kdb+ upgrades as you can do by pods and potentially leverage blue-green style deployments with pods containing different versions of kdb+.
This is just an example of how architectures may change. These would need to be explored further looking at how end of day save downs, hdbs and calculation engines are integrated within more complicated kdb+ architectures. It could, for example, be theorised that RDBs will never be used for save downs as WDB (Writing Database) pods are used instead and run in parallel having the only write access to any disks and then HDBs read access from the shared storage.
This proof of concept has provided us insight into the way kdb+ architecture could evolve and how we may need to think differently as we move into the modern world of containerisation and horizontally scalable systems.
Share this:















