Data Intellect
Kafka is a distributed messaging service used to achieve a low-latency, high-throughput transfer of data using persistent logs to prevent loss of data.
This blog will:
- Illustrate the various components used in Kafka.
- Show how Kafka can be used to share data between different technologies, for example, a Java producer and a kdb+ consumer.
- Highlight a use case for Kafka where it will be used in place of a tickerplant to emphasise the positives and negatives of the approach.
Kafka Components
We can break Kafka down into 6 main components:
- Zookeeper
Zookeeper manages the Kafka broker(s) and topic configuration(s).
- Producer
The producer pushes messages on to the Kafka broker.
- Consumer
The consumer pulls messages from the Kafka broker.
- Broker
The Kafka broker is responsible for sending and receiving messages from the consumer and producer respectively. A Kafka cluster is made up of multiple brokers.
- Topic
Messages can be categorised into topics. This allows a producer to send messages to the broker, and a consumer to receive those messages.
- Partition
When starting a Kafka topic, we can choose to split it into a number of partitions. This allows for the messages to be split across multiple brokers or machines. If the topic was started with a replication factor greater than one then for each partition group one will be assigned as the leader and the rest will be followers.
For more information on these components, visit the Apache documentation site here.
Implementation Overview
The example Kafka cluster below consists of a single broker, which mediates communication between a Java producer and a kdb+ consumer.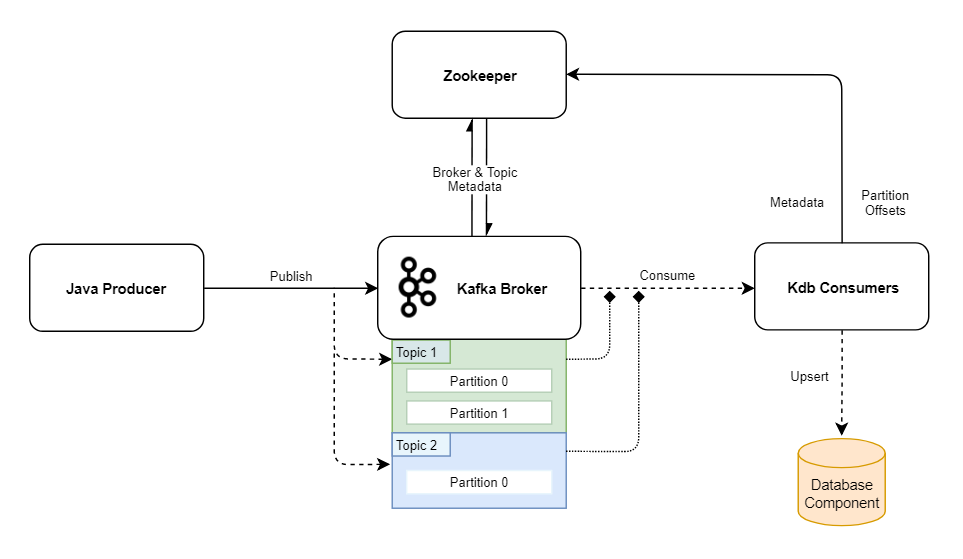 In this example, the data is stored in two topics, Topic 1 (two partitions) and Topic 2 (one partition), both created with a replication factor of 1. As there is only one broker available in this cluster, it is assigned both topics by default.
In this example, the data is stored in two topics, Topic 1 (two partitions) and Topic 2 (one partition), both created with a replication factor of 1. As there is only one broker available in this cluster, it is assigned both topics by default.
Zookeeper has a minimal role in this cluster. It is responsible for storing offsets (think message id) and as there is only one broker we do not need to worry about leadership and replicas (explained below). Metadata is passed between Zookeeper and the brokers to keep track of topics created and message offsets.
Data is stored in Kafka partitions as byte arrays, so to consume from or publish to a topic, data serializers must be set to cast the messages. Within the Java producer, the pre-serialized messages are stored as strings, so Kafka’s default StringSerializer class is used to convert both the ‘key’ (target topic) and ‘value’ (message).
Producer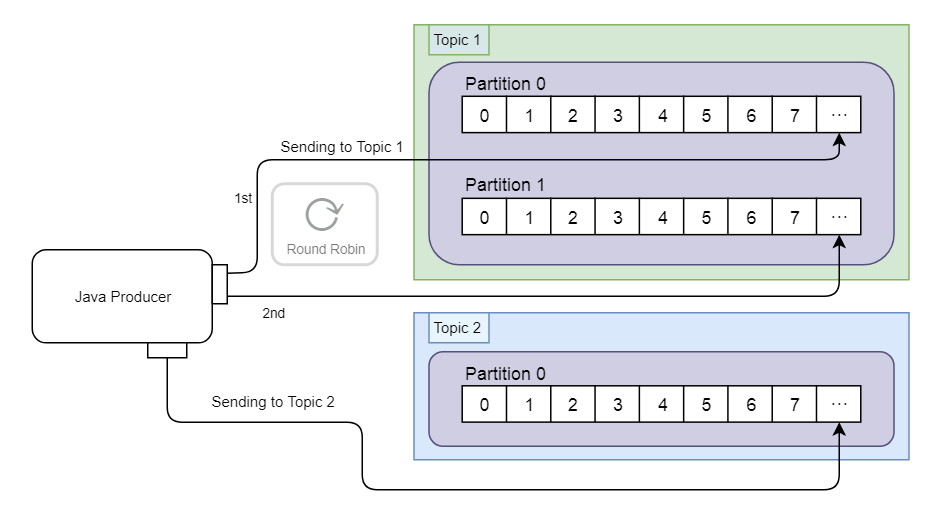
The Java producer is built using Spring for Apache Kafka. There is a configuration class which sets the String Serializer class as the key and value serializer and provides the bootstrap servers.
There is a producer class which uses the KafkaTemplate to send the message from within a method called send, which takes in the topic name and payload of the message as string parameters.
This is called within the main Springboot class, with different messages sent by invoking the send method. The messages in this example detail trade executions and are represented as JSON strings. The data passed in Kafka messages is serialised, and this allows the producer and consumer to be customised with serialisers and deserialisers. There are built-in Serialisation/Deserialisation libraries for strings, longs, byte arrays, byte buffers as well as JSON, ProtoBuf or Avro. Alternatively, we could customise our own.

JSON Strings
After the message is sent, the contents are converted to byte array and added by the broker to the relevant topic. From this point onward a consumer can claim it.
Consumer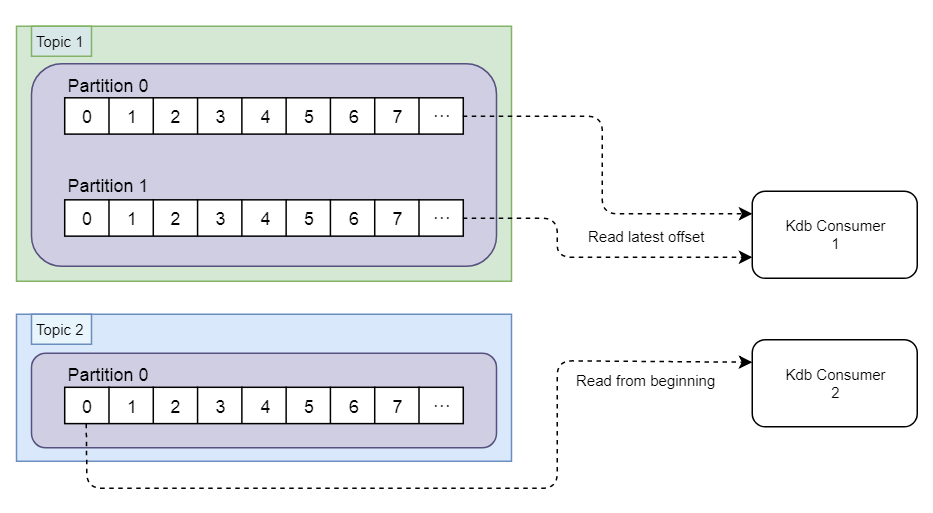
The two consumer instances are built using KX’s kfk module, which is a ‘thin wrapper for kdb+ around librdkafka C API for Kafka’. It should also be noted that the librdkafka library can be used for building kdb+ based producers as well.
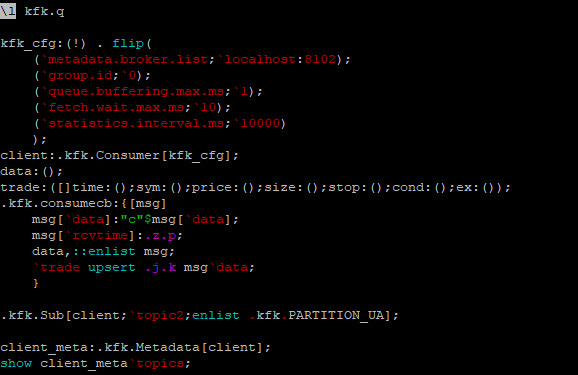
Consumer Code
The consumer properties are set within kfk_cfg. These are passed to the the .kfk.Consumer function, which instantiates a rd_kafka_t object (base librdkadka container). This object is then used with the .kfk.Sub function to subscribe to a topic that will be consumed from.
The main logic for message consumption is contained in .kfk.consumecb. This casts new messages to strings, adds a “receive time” field and stores the message in a meta table “data”. The JSON message is then parsed and upserted into the “trade” table.
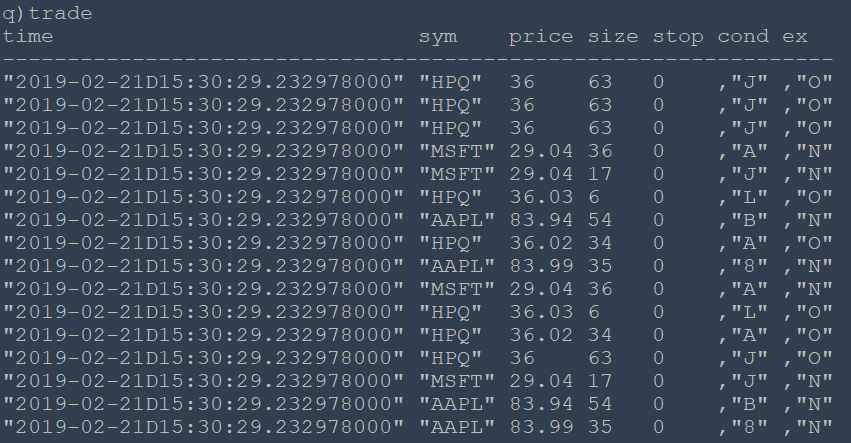
Output Table
We can create a second consumer by passing `topic1 to the kfk.Sub function. When running together, these two kdb+ sessions can consume any trade messages sent by the Java producer to our cluster.
Kafka kdb+ Use Case
In the previous section, we provided a simple example of using Kafka between a Java producer and a kdb+ consumer. Lets now look at how this can be applied to a real-world system, by replacing a kdb+ tickerplant with a Kafka cluster.
Setup with a Tickerplant
With a real-time kdb+ system (using TorQ or kdb+tick) we might have a layout that looks something like: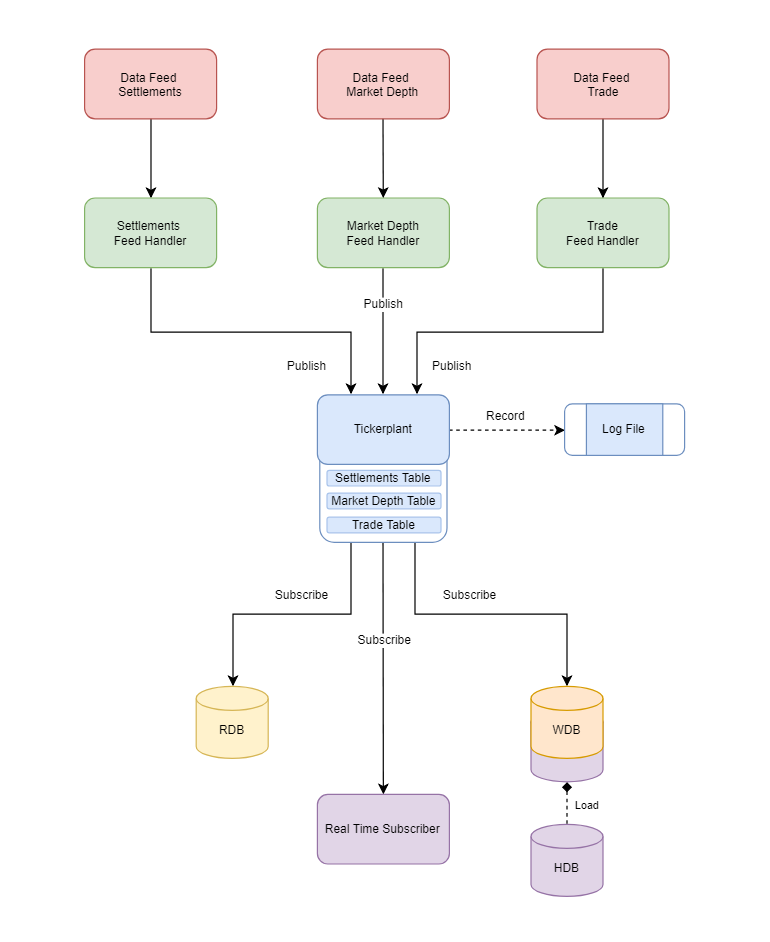 At the top we have data feeds and the respective feed handlers, that will convert the data streams into a format compatible with kdb+. At the bottom we have the underlying real-time and historical processes that will leverage the data.
At the top we have data feeds and the respective feed handlers, that will convert the data streams into a format compatible with kdb+. At the bottom we have the underlying real-time and historical processes that will leverage the data.
Between these publishers and subscribers we have the tickerplant, which coordinates the flow of data from the feed handlers to the subscribing processes. The tickerplant will write all of the incoming data to a log file to avoid loss of information in the event of a failure.
Pros of a standard tickerplant:
- Tried and tested, out of the box integration within the kdb+ tick setup.
- Built for speed with a low processing overhead.
- Real-time subscribers can benefit from receiving data at a high throughput.
Cons of a standard tickerplant:
- No native log file replication/backup. Corruption of the log file could result in permanent data loss.
- Single point of failure with the tickerplant process.
- In a real world environment, it is critical that real-time subscribers can finish processing an incoming update before the next one arrives. Complex subscriber processes may not be able to keep up with the tickerplant publishing rate. Solutions for this (i.e. chained tickerplants) can cause additional system overhead.
- Not easily scalable.
Replacing a Tickerplant with Kafka
Now having established and discussed the tickerplant setup, we will explore the impact of replacing the tickerplant with a Kafka broker.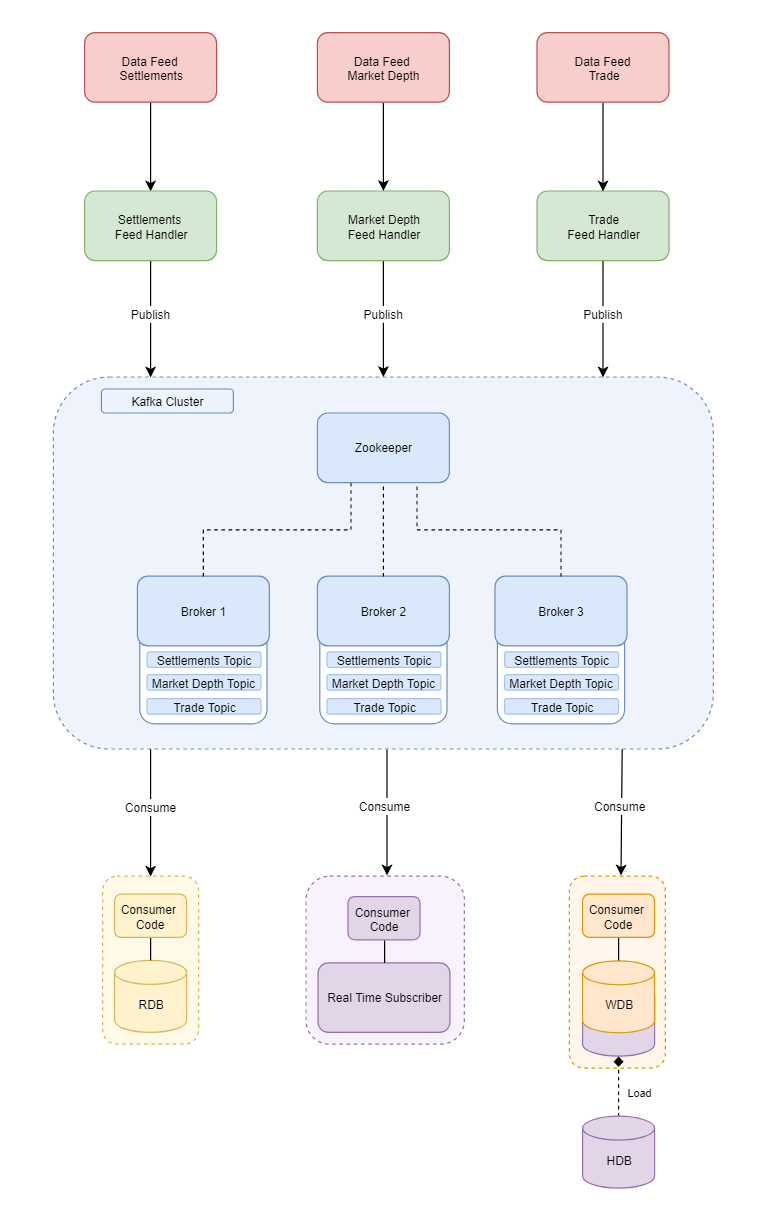
As you can see from the diagram: we take the tickerplant out and put Kafka broker clusters in. When we dive deeper we can see how Kafka will modify the existing setup. The cluster has 3 brokers each with topics on them.
Kafka Partitions
For speed of use and reliability we can increase the partitions. This is illustrated in the diagram below.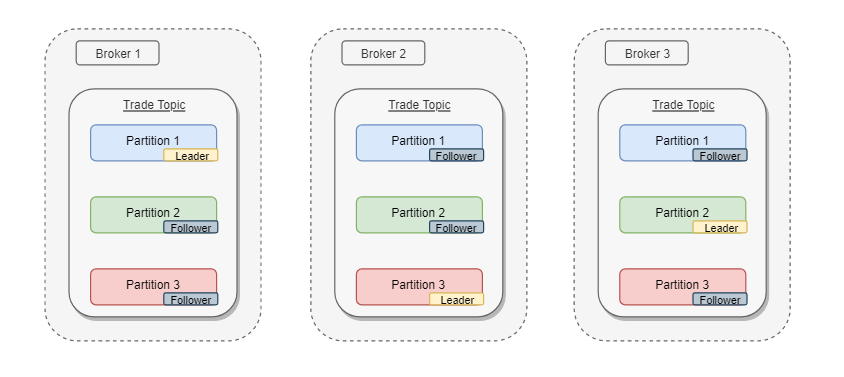 The three brokers can be on different machines in different countries if we wanted. This allows for the brokers to maintain service in the case of one broker going down. Replication factor is set when first setting up the topic and defines how many times a topic will be replicated across the brokers. If we take the trade topic as an example, it is replicated 3 times and as we have 3 brokers each gets one copy of trade, so each broker now has a trade topic. The topic itself is also split into 3 partitions each storing the message and meta data (id, timestamp, offset etc).
The three brokers can be on different machines in different countries if we wanted. This allows for the brokers to maintain service in the case of one broker going down. Replication factor is set when first setting up the topic and defines how many times a topic will be replicated across the brokers. If we take the trade topic as an example, it is replicated 3 times and as we have 3 brokers each gets one copy of trade, so each broker now has a trade topic. The topic itself is also split into 3 partitions each storing the message and meta data (id, timestamp, offset etc).
The partitions all aim to have identical data and the broker will assign one partition per topic as the leader. This means that all reads and writes come from this partition. The other two versions of the partition for the topic will be followers.
If the leader were to stop responding to the broker for any reason, the broker will select one of the followers to become the new leader, enabling the application to survive and adding a safety net. Followers will attempt to remain in sync with the leader, if they fail to do so they will be marked as out of sync and cannot be elected leader until they are back in sync.
Kafka Flow Description
We receive the data from the external source and feed it to our Kafka producer, using the producer to send our data to the broker. Kafka is not coupled with any language. We can send the message in a form that is not specific to kdb+, in this case key value pairs with the messages then placed on a topic. The benefit of this is that we are not limiting ourselves to kdb+; a Java consumer, Scala consumer or C# consumer can be written which collects the same messages from the topic and has access to the data.
The data stored on the topic is usually ordered by when it arrives at the broker and each message on the topic is given an offset which is stored on the partition with the message.
Data within the broker is kept for a specified amount of time (e.g. 7 days or after a certain amount of memory has been used) this is configured on topic creation. After this threshold is reached the oldest messages are deleted first. This idea of message retention allows for user to replay the messages by changing the group id of the consumer and restarting.
After the message has been added to the topic a consumer can consume it. As previously mentioned this consumer can be written in kdb+, Java, C#, or any technology that has Kafka implementation. The drawback from the kdb+ side would be that extra care has to be taken as all messages are sent as strings and the types must be parsed correctly on the kdb+ side. Once the consumer has subscribed to the message the data can then be parsed and used.
Pros & Cons
Pros of a Kafka implementation:
- Looser coupling with kdb+ allows users to consume data on different technology stacks.
- Better safeguards on failure.
- Simpler to write feed handlers and share data.
- Clients needing to replay data don’t have to exist on the tickerplant host.
- Kafka is specifically designed for data distribution.
Cons of a Kafka implementation:
- Kdb+ requires type conversion for each consumer, although it should be noted that different message formats for the data could help this.
- Introducing additional technologies which require expertise.
Conclusion
Kafka is a fast messaging system, it provides the user with fail-safes to allow for data to be replayed, can support the majority of technologies and messages are not coupled to one technology. This makes Kafka a useful tool for developers.
Kafka is not a silver bullet that eliminates all problems and gives us a perfect implementation of messaging. The individual Kafka and tickerplant setups must be designed for the specific problem. If there are multiple different technologies consuming the information or you require a high level of fail-safes with your messaging, a Kafka-based setup may be more effective. If you need data to only go to a kdb+ process or are moving the data to multiple tables on a kdb+ process stack, then it may make more sense to use a tickerplant.
In summary Kafka is a fast messaging bus implementation but it isn’t perfect for every situation and should be used where needed.
Share this:















