Data Intellect
Accessibility is important for all software, it provides a pleasant user experience as well as a seamless interaction with non-native processes. The Data Access API provides TorQ with a sleek user interface as well as accessible and extensive functionality to both the inexperienced kdb+ user and non kdb+ processes. Whilst experienced kdb+ developers will likely prefer to write queries directly, the Data Access API allows the same request to be run across multiple different end points (including non kdb+) and more complex joins automatically across different data sources.
This blog highlights how Data Access API has achieved its goals through:
- Compatibility with non kdb+ processes such as Google BigQuery and qREST
- Consistent queries across all processes
- Data retrieval does not require q-SQL knowledge only q dictionary manipulation
- User friendly interface including more comprehensible error messages
- Queries are automatically optimised for each process
- Thorough testing allowing ease of further development
Download and installation can be found at our github repo and full documentation here.
Usage
The getdata function provides a dynamic lightweight access point to a process. getdata takes in a uniform dictionary type (see table below) to build a bespoke query. Input consistency permits getdata to be called either directly from within a process or at a gateway.
| Parameter | Example | Description | Required |
|---|---|---|---|
| tablename | `quote | Table to query | Yes |
| starttime | 2020.12.18D12:00 | Start time | Yes |
| endtime | 2020.12.20D12:00 | End time | Yes |
| timecolumn | `time | Column to apply time filter to | No |
| instruments | `AAPL`GOOG | Instruments To filter on | No |
| columns | `sym`bid`ask`bsize`asize | Table columns to return | No |
| grouping | `sym | Columns to group by | No |
| aggregations | `last`max!(`time;`bidprice`askprice) | Dictionary of aggregations | No |
| timebar | (`time;10;`minute) | Time grouping | No |
| filters | `bid`bsize!(((<;85);(>;83.5));enlist(not;within;5 43)) | Filters | No |
| freeformwhere | “sym=`AAPL, src=`BARX, price within 60 85” | kdb where clause | No |
| freeformby | “sym:sym, source:src” | kdb by clause | No |
| freeformcolumn | “time, sym,mid:0.5*bid+ask” | kdb select clause | No |
| ordering | enlist(`desc`bidprice) | column to sort result by | No |
| optimisation | 0b | Toggle getdata’s built in optimiser | No |
| renamecoloumn | `old1`old2`old3!`new1`new2`new3 | Column renaming dictionary | No |
| sublist | 6 | Take the top n rows | No |
Above all, the variety of arguments strike an important balance between accessibility and simplicity. Allowing, yet not enforcing, dictionary manipulation provides an access point to all users. The following two code snippets reinforce this point:
q)getdata`tablename`starttime`endtime`instruments`columns!(`quote;2000.01.01D00:00;2000.01.06D10:00;`GOOG;`sym`time`bidprice`bidsize`askprice`asksize)
sym time bidprice bidsize askprice asksize
---------------------------------------------------------------------
GOOG 2000.01.01D00:00:00.000000000 97.2 959.4 118.8 1172.6
GOOG 2000.01.01D02:24:00.000000000 90.9 932.4 111.1 1139.6
GOOG 2000.01.01D04:48:00.000000000 98.1 933.3 119.9 1140.7
GOOG 2000.01.01D07:12:00.000000000 94.5 939.6 115.5 1148.4
GOOG 2000.01.01D09:36:00.000000000 93.6 925.2 114.4 1130.8q)getdata`tablename`starttime`endtime`freeformcolumn`freeformby`timebar!(`quote;.z.d+00:00;.z.p;"avgmid:avg 0.5*bid+ask";"sym,src";(`time;6;`hour))
sym time src | avgmid
----------------------------------------| --------
AAPL 2021.01.19D12:00:00.000000000 BARX | 84.15385
AAPL 2021.01.19D12:00:00.000000000 DB | 84.18419
AAPL 2021.01.19D12:00:00.000000000 GETGO| 84.15667
AAPL 2021.01.19D12:00:00.000000000 SUN | 84.375The first snippet shows the API accepting exclusively simple arguments. By contrast, the second snippet demonstrates the API executing a more traditional kdb+ query, both returning the expected results. No timecolumn argument has been provided, as the API has used a default time column.
The API also provides a function to build, yet not execute, a query. This allows for faster debugging.
q).dataaccess.buildquery `tablename`starttime`endtime`freeformcolumn `freeformby`timebar`instruments!(`quote;.z.d+00:00;.z.p;"avgmid:avg 0.5*bid+ask";"sym:sym,src:src";(`time;6;`hour);`AAPL)
? `quote ((=;`sym;,`AAPL);(within;`time;2021.01.20D00:00:00.000000000 2021.01.20D08:47:55.058354000)) `sym`time`src!(`sym;({[n;x]
typ:type x;
timebucket:n*0D00:00.000000001;
...Logging functionality has also been added, allowing a developer to quickly unpick a bad query. The below table is populated with queries to the API from both the GW and within the process.
.dataaccess.stats:([querynumber:()]user:();starttime:();endtime:();handle:();request:();success:();error:())The Gateway
From within the gateway the user sees the greatest extension of functionality. This is because same the uniform dictionary can be sent to multiple processes and the results joined back together. The process is simple (see diagram):
- The user calls
.dataaccess.getdata inputdictionary - The input dictionary has its inputs checked in the gateway
- The routing function then selects the process(es) to query
- The gateway calls
getdata(inputdictionary)in each process - The joining function glues the results back together
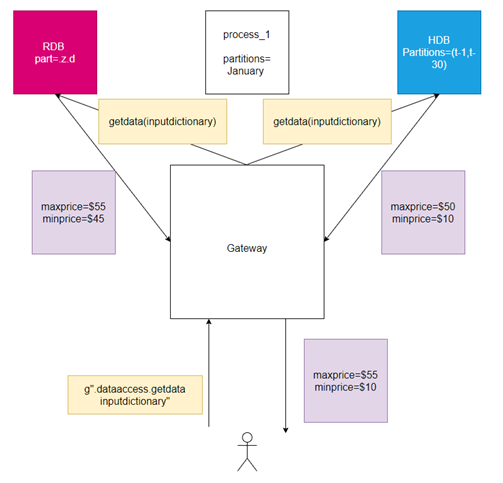
The resulting code can be seen below:
q)g"querydictyesterday"
tablename | `quote
starttime | 2021.02.08D00:00:00.000000000
endtime | 2021.02.09D00:00:00.000000000
aggregations| `max`min!(`ask`bid;`ask`bid)
q)g"querydicttoday"
tablename | `quote
starttime | 2021.02.09D00:00:00.000000000
endtime | 2021.02.09D09:00:00.000000000
aggregations| `max`min!(`ask`bid;`ask`bid)
g"querydict"
tablename | `quote
starttime | 2021.02.08D00:00:00.000000000
endtime | 2021.02.09D09:00:00.000000000
aggregations| `max`min!(`ask`bid;`ask`bid)
q)g".dataaccess.getdata querydictyesterday"
maxAsk maxBid minAsk minBid
---------------------------
214.41 213.49 8.8 7.82
q)g".dataaccess.getdata querydicttoday"
maxAsk maxBid minAsk minBid
---------------------------
94.81 93.82 8.43 7.43
q)g".dataaccess.getdata querydict"
maxAsk maxBid minAsk minBid
---------------------------
214.41 213.49 8.43 7.43Another extension the API provides is compatibility with q-REST users can send requests in json form to the gateway see the documentation for a complete explanation.
Under the Hood
The getdata function is split into three sub functions: checkinputs, extractqueryparams and queryorder.
Checkinputs
The checkinputs function takes the input dictionary and runs various checks on each of the passed parameters before executing the query. The function scrutinizes queries to catch errors before they happen as well as return useful error messages such as:
q)getdata `tablename`starttime`endtime`freeformby`instruments!(`notAtable;.z.d+00:00;.z.p;"sym:sym";`AAPL)
'table:`notAtable doesn't existQueryorder
Queryorder is where the query is rearranged to return a consistent succession of aggregations as well as optimising the performance.
Firstly, the by clause is ordered date, sym, then other aggregations.
q)getdata`tablename`starttime`endtime`freeformcolumn`freeformby`timebar!(`quote;.z.d+00:00;.z.p;"avgmid:avg 0.5*bid+ask";"sym:sym,src:src";(`time;6;`hour))
sym time src | avgmid
----------------------------------------| --------
AAPL 2021.01.19D12:00:00.000000000 BARX | 84.15385
AAPL 2021.01.19D12:00:00.000000000 DB | 84.18419
AAPL 2021.01.19D12:00:00.000000000 GETGO| 84.15667
AAPL 2021.01.19D12:00:00.000000000 SUN | 84.375The returned columns have been reordered to create a more intuitive response. Although technically a restriction to the experienced developer, the accessibility far outweighs this. Moreover, queryorder improves the speed of a query (see performance).
q).dataaccess.buildquery `tablename`starttime`endtime`freeformcolumn`freeformby`instruments!(`quote;.z.d+00:00;.z.p;\"mprice:max ask\";\"sym:sym,src:src\";`AAPL)
? `quote ((=;`sym;,`AAPL);(within;`time;2021.01.20D00:00:00.000000000 2021.01.20D09:19:22.689811000)) `sym`src!`sym`src (,`mprice)!,(max;`ask)Extending the getdata function would require additions to all three sub-functions as well as extensive testing. The data access API has a vast testing library.
Performance
The returned query is written in kdb+ hence the performance of getdata and a well written query is similar. By default, queryorder automatically reorders the where clause to ensures a consistently good query speed for all API users. This can be toggled off by setting optimisation to 0b in the input dictionary.
To determine the effectiveness of the API, tests were carried out across three 5Gb HDB with 22 partitions and a RDB. Each setup had a varying number of syms. The following queries were tested:
| Queryname | Call |
| Optimised1 | `tablename`starttime`endtime`freeformby`aggregations`freeformwhere)!(`quote;00:00+2020.12.17D10;.z.d+12:00;\”sym\”;(`max`min)!((`ask`bid);(`ask`bid));\”sym in `AMD`HPQ`DOW`MSFT`AIG`IBM |
| kdb1 | select max ask,min bid,max bid,min ask by sym from quote where sym in `AMD`HPQ`DOW`MSFT`AIG`IBM |
| Optimised2 | (`tablename`starttime`endtime`aggregations`timebar)!(`quote;2021.02.23D1;.z.p;(enlist(`max))!enlist(enlist(`ask));(6;`hour;`time)) |
| kdb2 | select max ask by 21600000000000 xbar time from quote where time>2021.02.23 |
| Optimised3 | (`tablename`starttime`endtime`filters!(`quote;2021.01.20D0;2021.02.25D12;`bsize`sym`bid!(enlist(not;within;5 43);enlist(like;\”*OW\”);((<;85);(>;83.5))))) |
| kdb3 | select from quote where bid within(83.5;85),not bsize within(5;43),sym like \”*OW\” |
The unoptimsed columns are the identical query as the retrospective optimised ones however with optimisation set to 0b.
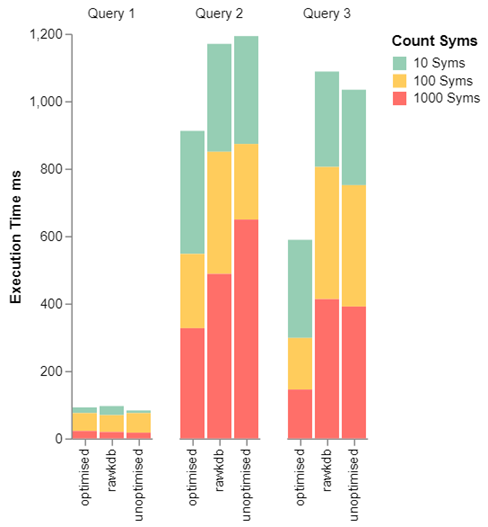
The results and full methodology can be seen in the documentation. Each section of the graph highlights key functionality of the API:
- Query 1 Shows a typical optimised query from inside and outside the API, the performance difference is negligible. Demonstrating the
getdatafunction as fast and lightweight. - Query 2 Highlights the power of the configuration lead architecture. The raw kdb query doesn’t use the partitioned structure of the HDB, whilst tableproperties.csv ensures the API uses this for a solid performance boost.
- Query 3 Demonstrates the performance boost of queryorder reordering the where clause to prioritise the sym column – making it approximately twice as fast.
Conclusion
In conclusion, there is no doubt the API has provided a simple, yet unrestrictive, access point to TorQ. This has been achieved by:
- The variety of
getdatainput arguments maintain freedom for the developer whilst creating a better user experience. - The gateway provides seamless multi-process interface.
- The helpful error messages allow provide a detailed insight into their bad query allowing it to be quickly repaired.
- The toggleable automatic query optimisation ensures bad queries never hit a process.
The API’s interaction with Google BigQuery is complete, further information will be provided in a future blog post.
Share this: