Gary Davies
In a data driven world, the ability to access and retrieve data efficiently is critical. This means data needs to be readily available to users, and in the kdb+ world this can present a challenge. kdb+ being somewhat single threaded can result in heavy users acting greedily on data processes.
In AquaQ we are hearing more from our clients about the need to scale to meet user demand for historical data, and there are two key drivers behind this. The first has been highlighted above; more users than the current architecture can handle. Adapting to this demand is costly in resources and time.
The second driver is the reverse, when users aren’t overly active there will be unused processes consuming resources, which can also be costly. Traditionally this has been less of a problem as kdb+ has been deployed on-premise with a fixed hardware footprint. Cloud allows dynamic scaling of hardware, and the scale down aspect is as an important lever to help reduce costs.
We have been working on addressing this concern to create a configurable, automated solution which this blog will walk through.
This solution has been implemented on client and internally within AquaQ, both using on-premises hardware leveraging kdb+ and Kubernetes.
The concept however, is agnostic to platform with kdb+ and Kubernetes being available across cloud platforms. The difference would be that the cloud implementation would involve cloud based storage, for example an object store or a distributed file system approach.
Problem
In defining kdb+ architectures we usually consider a single HDB instance per dataset at the outset and this provides our initial implementation. As users are onboarded, and demand increases, then the number of instances of these datasets can be increased as necessary through some code or configuration, a quality assurance cycle and production release.
From this point on, demand is typically measured through the appearance, and increase, of user complaints on data availability, or increased waiting times. As this occurs developers implement further instances through more code or configuration.
It is not often that we ever scale down databases, with the only real driver to do this being a lack of hardware resources.
This presents a number of problems:
- There is limited quantitative insight into the demand on the data.
- Scaling processes typically requires manual intervention at best and a code release cycle at worst.
- Scaling up takes time and demand may have changed before this occurs.
- Scaling down doesn’t happen often, which can leave stagnant processes that are not doing anything but still need to be actively monitored.
In summary a typical kdb+ HDB cannot be easily scaled to meet the change in demand from users. This is an issue that many kdb+ applications face and it is something that we have been looking to address, both internally and on client projects.
Solution
In a previous blog, AquaQ highlighted the rise in recent years toward containerization of software solutions and created a proof of concept focusing on kdb+ in a multi-technology real-time solution. Containerization provides us the scalability that is needed to be able to get closer to matching supply and demand in an automated manner.
We have taken the lessons learned from this previous PoC, in addition to the problem presented above, and worked on creating proof of concepts both internally and as part of a real-world client project.
Using the AquaQ TorQ open source framework we are able to focus the architecture on 3 key components; HDB, discovery and the gateway. Discovery is needed to enable us to understand available processes and their health, while the gateway provides a single access point for the historical data.
Each of the components is housed within their own container using Kubernetes, although at this stage the intention is only to scale the HDB containers.
This allows us to create an architecture as depicted below:
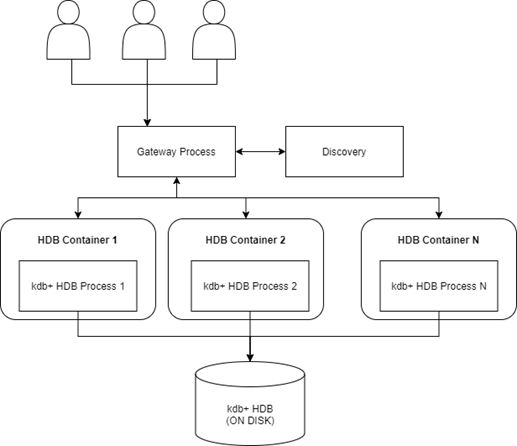
This system presented us with some questions:
How do we load balance the queries?
If we assume that all user queries completed within a small time period then it makes sense that we could use one of the pre-defined default Kubernetes service routing. Using this would mean that service routing could follow a standard like round-robin or random in identifying which pod to go to. This makes sense if the load and time is consistent, but as we know users of kdb+ systems are not always predictable and use cases change drastically in HDBs from small data pulls to year-to-date to even larger. As such round robin resulted very quickly in some of our HDBs having large queues of queries versus some being available. It just wasn’t possible for Kubernetes to understand what queries existed where.
As such for our project we decided that discovery, through TorQ, has an awareness of any pods that are started up, and the gateway has an understanding of the availability of these given queries are routed through it. Therefore we implemented procedures to ensure that queries from the gateway always went to the first pod UNLESS it wasn’t available due to someone querying then it would take the second and so on. This means that the system just takes the first that’s not being queried and provides us an efficient way to load-balance across.
This is demonstrated in the image below where you can see the status change in our available processes. If the hdb is in-use (inuse column) then it is still busy and won’t be accessed. Once the query is complete it comes back into service.
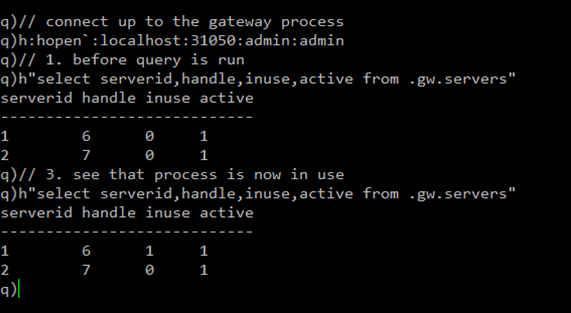
It is worth also noting that our end users of this architecture have no means of contacting the hdb pods as their IPs/ports are not externally exposed. The only entry point is through the gateway, with the gateway being able to access the pods within the cluster.
How do we access the data on disk?
A standard kdb+ set up typically uses one of the following:
- 1 HDB corresponding to 1 on disk database
- Multiple HDBs corresponding to 1 on disk database
- Multiple versions of the on disk database (Disaster Recovery) and either of the above
In the containerized architecture we do not want the HDB data to exist within the pod. This would create the requirement for potentially huge amounts of disk space and also data duplication with each pod that arises. Therefore we decided upon providing access to the data storage. Our servers housing this are bare-metal so we provided the containers read-only access to the database directory ensure that the pods could see it but never modify anything associated with it. This would also work in a cloud based architecture, though the data storage would likely be an object store with built in replication. It is assumed that in the bare-metal system using this that some form of disaster recovery exists for the data, either from tape back up or 2 independent sites.
When do we scale?
This is a critical question in a containerized approach, we want to able to provide the supply to match the demand but what defines demand? Our architecture currently provides 2 means for scaling through Kubernetes, memory based or CPU. For the running of the system, we determined that CPU made the most sense as a metric for scaling when dealing with HDBs. As such the Kubernetes cluster is monitoring the CPU usage of its pods over time periods and using our customizable thresholds will determine if it requires more pods.
If another pod is required it will launch one, provided it doesn’t exceed the maximum allowed which is another customizable threshold.
That handles the scaling up, but the monitoring is also watching for when pods are not actively being used and will reduce periodically the HDBs down over time until it reaches the customizable minimum.
We can also configure the rate of increase, the number of pods increased/decreased in a given timeframe, so scaling up and down is more gradual. This prevents thrashing in the system as realistically you don’t want to jump from 1 to 20 and vice versa.
These metrics allow a highly customizable scaling approach to applications.
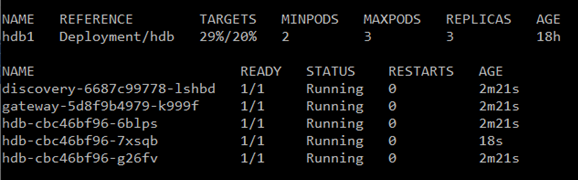
The image below shows the hpa (horizontal pod autoscaler) and pod information. This was captured as our application began scaling up an additional hdb (hdb-cbc46bf96-7xsqb) which has an age of 1 second and is currently being created.

The hpa information includes:
- TARGETS: This is the current and breach condition value to determine whether scaling is needed. In this case the current value is 26{e673f69332cd905c29729b47ae3366d39dce868d0ab3fb1859a79a424737f2bd} CPU which exceeds our limit of 20{e673f69332cd905c29729b47ae3366d39dce868d0ab3fb1859a79a424737f2bd} and has resulted in the additional pod being launched.
- MINPODS: This is the minimum number of pods in the system, in our case there will always be at least 2 active. If one of the two died it would automatically bring another up.
- MAXPODS: This is the maximum number of allowed hdb pods.
- REPLICAS: This is the number of active pods that are up and accessible. Note that the 3rd hdb pod is not yet up so not represented
The pod information includes:
- NAME: The name of the pod, in our application this shows the type of process and then the unique identifier which is the host name of the pod.
- READY: This is whether the pod is ready
- STATUS: The current status of the pod
- RESTARTS: The number of restarts each pod has had
- AGE: The lifetime of each of the pods
Once the new pod is ready, the status will change as shown below.
There is an additional scenario to consider around scaling, and that is what to do in a failure scenario. Pods allow us to make use of memory limits so we can have them fall over in the scenario of a bad query. This is similar to what would happen in a typical kdb+ system but the difference here is that Kubernetes will bring another pod up in the system, ensuring availability is maintained. This is all performed automatically without support or developer intervention, and like everything above, is customizable through configuration.
Conclusion
The creation and implementation of this solution has demonstrated to us that containerization is something that should be leveraged more within kdb+ architectures, providing the following advantages:
- Provides the means to automatically scale to meet demand (either up or down)
- Reduces manual touch points from development & support
- Removes server specific configuration
- Containers can be made read only to avoid any potential updates or deletes
- The kdb+ processes can be “hidden” to users with all access through a managed gateway
- Allows us to leverage monitoring solutions like prometheus
- Moves towards a cloud based architecture that can also be leveraged on premise.
At AquaQ we are continuing to investigate the use of containers as a means to automatically scale other aspects of the kdb+ architecture as we look toward the creation, design and implementation of more dynamic solutions.
If this post has piqued your interest and you would like to hear more about our containerized solutions or have a demo please do reach out and ask, you can do so by dropping a mail to info@aquaq.co.uk.
Share this:















