TorQ v2.6 – kdb+ v3.4 Functionality Rolled In
Glen Smith
The latest release of TorQ can be found here. For this release we focused on two areas : incorporating new features from kdb+ v3.4 and improving our own processes.
Unix Domain Sockets and SSL/TLS
Our IPC library can now make use of Unix domain sockets (UDS) and SSL/TLS which have been added to kdb+ v3.4. UDS are not backwards compatible so we included a fallback option. If enabled, any failed UDS connection will fallback to the default TCP. Fallback is not turned on for SSL/TLS due to security reasons.
The connection method is specified per proctype (process type- basically a high level classification of the functionality of the process). So a process will check what IPC mechanism to use before connecting to another process. These are specified in the .servers.SOCKETTYPE dictionary. In the example below, any connection created to the tickerplant process types will use UDS and similarly SSL/TLS for the gateway process types.
// ipc mechanisms : `unix`tcps`tcp
q).servers.SOCKETTYPE
tickerplant| unix
gateway | tcps
q).servers.SOCKETFALLBACK
1bUsing UDS on windows is disabled, even though the connection will be successful as kdb+ will fall back to TCP in the background- this is to avoid misleading the user. You also cannot use UDS to connect to a process on a different host.
Broadcast
The broadcast feature which was added in kdb+ 3.4 is now included in our publish code and is enabled by default. It can be disabled by setting .u.broadcast to false. The benefit of using this feature is that it spends less time publishing common messages to multiple subscribers.
New Gateway Functionality
Previously gateway queries required users to specify the process types that they wanted the query to run against, e.g. rdb, hdb. This functionality is still there but we have overloaded the argument so when passed a dictionary it will query based on server attributes. Any process can report process attributes by implementing the .proc.getattributes function call. Attributes can be anything. The gateway will use the dictionary of requested attributes supplied with a query to work out which processes it needs to access to fully service the query. Shown below are the two ways of querying the gateway, first using servertype and second using attributes. The attributes reported by each process are the list of tables it has available, the date range it has available and the list of syms it has available.
// passed a symbol list of servertypes. Backwards compatible!
q)h(`.gw.asyncexec;"select time,sym,price from trade";enlist `rdb)
...
// passed a dictionary of attributes
q)h(`.gw.asyncexec;"select time,sym,price from trade";`table`sym`date!(enlist `trade;`MSFT`IBM;enlist 2016.07.29))
To show this in action, we’ll look at a situation where the rdb and hdbs are striped, meaning that each has a different set of syms. You can see the setup in the figure below.
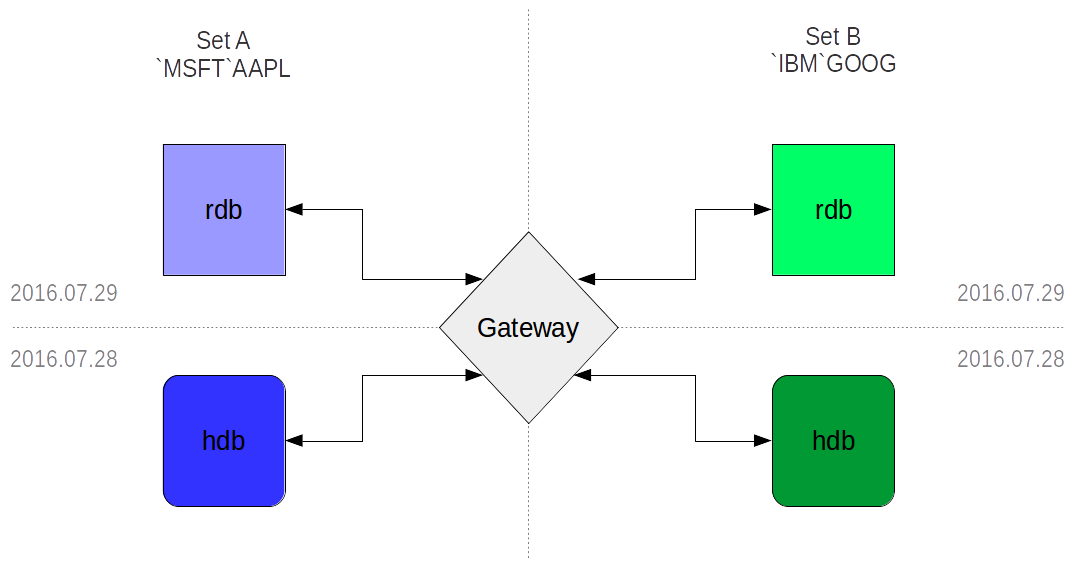
By looking at the internal gateway tables we are able to see which processes are accessed with the query and that they match the given attributes. Throughout these examples, I will be showing a table called wasHit, which is a result of a custom query against the gateway’s internal tables. With this, you’ll be able to see which processes were hit with the query and their attributes. This is used for demonstration only.
Query for syms across two rdbs
In this example we are going to query for two syms that are not contained by a single rdb but are present on each one. For this to work the gateway must see that the query needs to be run on two different processes.
q)h(`.gw.asyncexec;"select time,sym,price from trade";`table`sym`date!(enlist `trade;`MSFT`IBM;enlist 2016.07.29))
...
q)wasHit
serverid servertype date table sym hit
--------------------------------------------------
1 hdb 2016.07.28 trade MSFT AAPL 0
2 hdb 2016.07.28 trade IBM GOOG 0
3 rdb 2016.07.29 trade MSFT AAPL 1
4 rdb 2016.07.29 trade IBM GOOG 1 Query for syms across two hdbs
Same as above except it will query the hdbs.
q)h(`.gw.asyncexec;"select time,sym,price from trade";`table`sym`date!(enlist `trade;`MSFT`IBM;enlist 2016.07.28))
...
q)wasHit
serverid servertype date table sym hit
--------------------------------------------------
1 hdb 2016.07.28 trade MSFT AAPL 1
2 hdb 2016.07.28 trade IBM GOOG 1
3 rdb 2016.07.29 trade MSFT AAPL 0
4 rdb 2016.07.29 trade IBM GOOG 0 Query for syms across an rdb and hdb with the same sym set
This time you’ll see the queries going to the rdb and hdb with the same sym.
q)h(`.gw.asyncexec;"select time,sym,price from trade";`table`sym`date!(enlist `trade;enlist `MSFT;2016.07.28 2016.07.29))
...
q)wasHit
serverid servertype date table sym hit
--------------------------------------------------
1 hdb 2016.07.28 trade MSFT AAPL 1
2 hdb 2016.07.28 trade IBM GOOG 0
3 rdb 2016.07.29 trade MSFT AAPL 1
4 rdb 2016.07.29 trade IBM GOOG 0 Query that shows the date being taken into account
Whilst there are two processes that match the table and sym attributes, the date attribute only matches on the rdb.
q)h(`.gw.asyncexec;"select time,sym,price from trade";`table`sym`date!(enlist `trade;enlist `MSFT;enlist 2016.07.29))
...
q)wasHit
serverid servertype date table sym hit
--------------------------------------------------
1 hdb 2016.07.28 trade MSFT AAPL 0
2 hdb 2016.07.28 trade IBM GOOG 0
3 rdb 2016.07.29 trade MSFT AAPL 1
4 rdb 2016.07.29 trade IBM GOOG 0
Multiple copies of striped processes
For the case where there are multiple rdbs and hdbs with the same attributes, the gateway does what you’d expect and will query those that match the attributes and are currently free. In this example we’ll send a query that includes a sleep which blocks the process, during this time we’ll send another query and we’ll see the gateway sending it to a currently free process that matches the attributes.
The first query gets sent to the currently free processes with serverids 5 and 6, that match the attributes.
q)wasHit
serverid servertype date table sym hit
--------------------------------------------------
1 hdb 2016.07.28 trade MSFT AAPL 0
2 hdb 2016.07.28 trade MSFT AAPL 0
3 hdb 2016.07.28 trade IBM GOOG 0
4 hdb 2016.07.28 trade IBM GOOG 0
5 rdb 2016.07.29 trade IBM GOOG 1
6 rdb 2016.07.29 trade MSFT AAPL 1
7 rdb 2016.07.29 trade MSFT AAPL 0
8 rdb 2016.07.29 trade IBM GOOG 0 As the second query is sent, the gateway knows that servers 5 and 6 are currently processing a request whilst servers 7 and 8 with matching attributes are free. So the query is sent to them instead.
q)wasHit
serverid servertype date table sym hit
--------------------------------------------------
1 hdb 2016.07.28 trade MSFT AAPL 0
2 hdb 2016.07.28 trade MSFT AAPL 0
3 hdb 2016.07.28 trade IBM GOOG 0
4 hdb 2016.07.28 trade IBM GOOG 0
5 rdb 2016.07.29 trade IBM GOOG 0
6 rdb 2016.07.29 trade MSFT AAPL 0
7 rdb 2016.07.29 trade MSFT AAPL 1
8 rdb 2016.07.29 trade IBM GOOG 1 What’s the Point?
The purpose of this is to remove the requirement that applications/users of the data have to know which process type the data they are looking for resides in. Instead they just have to know the set of attributes that they can query for. Essentially you can place the gateway in front of multiple heterogeneous data sources and users have to know what they are looking for rather than where they are looking for it.
It should be noted that you are not restricted to using just `table, `date and `sym attributes. You can use any attributes you desire. Ideas include:
- querygroups – queries from different user groups go to a different set of servers e.g. queries from quants doing research will be sent to their own dedicated resources
- region – only send queries to servers instead of your data centre i.e. keep it local.
Heartbeat Subscriptions
Previous versions of TorQ all allowed heartbeats to be published to other processes. They didn’t include an easy way for processes to subscribe for and monitor heartbeats. With TorQ 2.6, if .hb.subenabled is set to true then the process will subscribe to heartbeats of processes specified by .hb.CONNECTIONS, which should be a subset of the connections in .servers.CONNECTIONS or `ALL, if you wish to subscribe to heartbeats for all available processes.
Enabling subscriptions sets custom definitions for .z.pc and .servers.custom, which monitor connections and subscribe to heartbeats on each handle as appropriate. Additionally a timer will periodically check for new connections from specified processes.
Feedback
We’d love to hear feedback on the changes made to TorQ, or things you’d like to see in future versions. Please get in touch!
Share this:












